为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
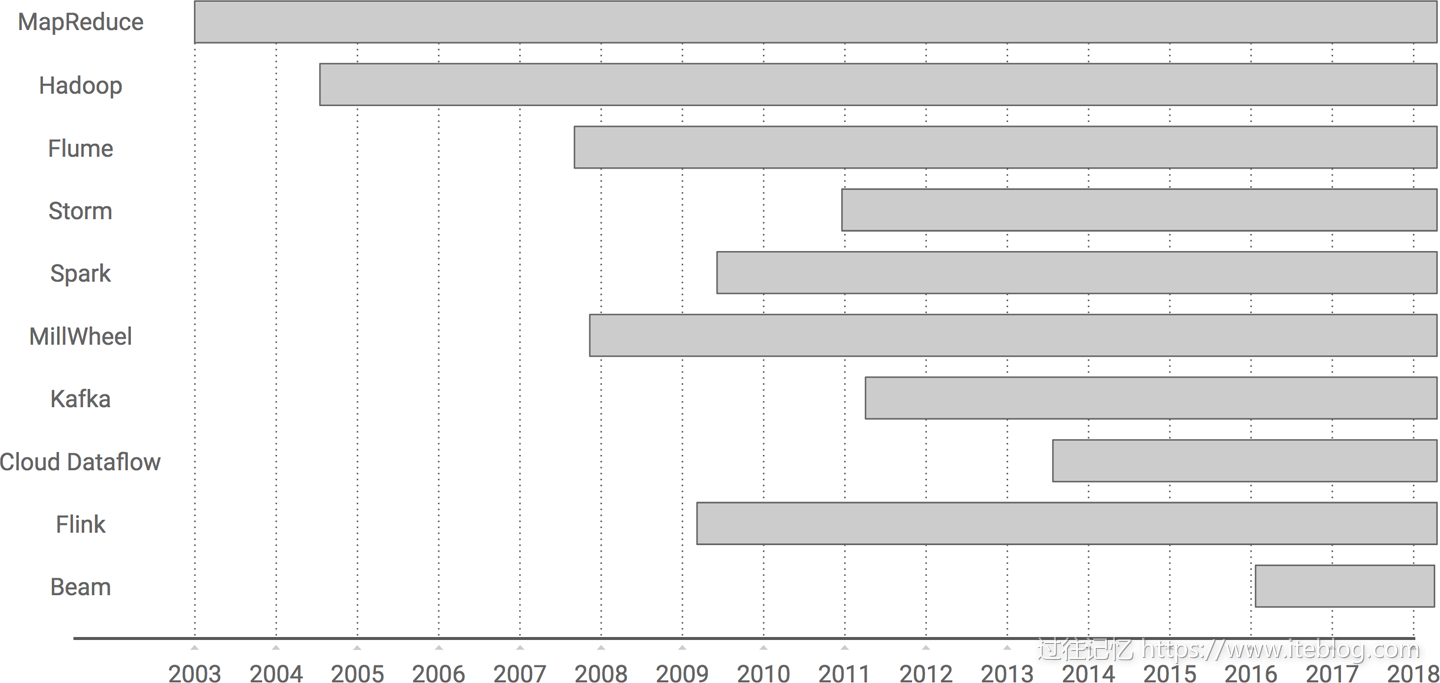
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10335℃ 2评论27喜欢
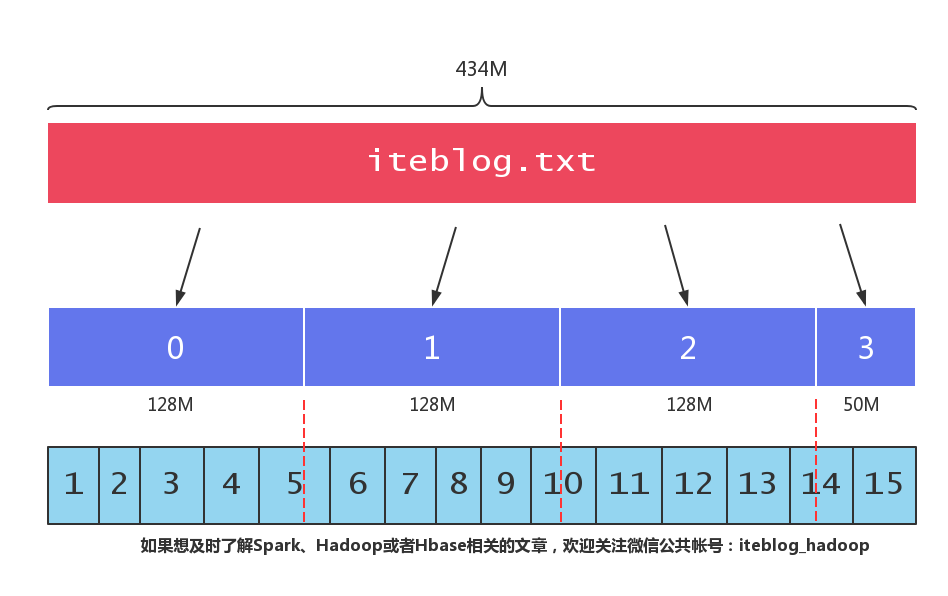
在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 w397090770 7年前 (2018-05-16) 2393℃ 0评论19喜欢
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2692℃ 4评论28喜欢
大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时候会遇到以下的异常:[code lang="java"]Exception in thread "main" jav w397090770 8年前 (2017-07-04) 5443℃ 1评论16喜欢
我在前面的文章介绍了MapReduce中两种全排序的方法及其实现。但是上面的两种方法都是有很大的局限性:方法一在数据量很大的时候会出现OOM问题;方法二虽然能够将数据分散到多个Reduce中,但是问题也很明显:我们必须手动地找到各个Reduce的分界点,尽量使得分散到每个Reduce的数据量均衡。而且每次修改Reduce的个数时,都得 w397090770 8年前 (2017-05-12) 7314℃ 14评论20喜欢
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序。但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序。基于此,本文提供三种方法来对MapReduce的输出进行全局排序。生成测试数据在介绍如何实现之前,我们先来生成一些测试数据,实现如下:[code lang="bash"]#! w397090770 8年前 (2017-05-10) 14577℃ 0评论29喜欢
大家在提交MapReduce作业的时候肯定看过如下的输出:[code lang="bash"]17/04/17 14:00:38 INFO mapreduce.Job: Running job: job_1472052053889_000117/04/17 14:00:48 INFO mapreduce.Job: Job job_1472052053889_0001 running in uber mode : false17/04/17 14:00:48 INFO mapreduce.Job: map 0% reduce 0%17/04/17 14:00:58 INFO mapreduce.Job: map 100% reduce 0%17/04/17 14:01:04 INFO mapreduce.Job: map 100% reduce 100%[/ w397090770 8年前 (2017-04-18) 3691℃ 2评论11喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer,从而充分利用 Hadoop 并行计算框架的优势和能力,来处理大数据。而我们在官方文档或者是Hadoop权威指南看到的Hadoop Streaming例子都是使用 Ruby 或者 Python 编写的,官方说可以使用任何可执行文件 w397090770 8年前 (2017-03-14) 2729℃ 0评论2喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 8年前 (2016-11-28) 17876℃ 2评论52喜欢







![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)