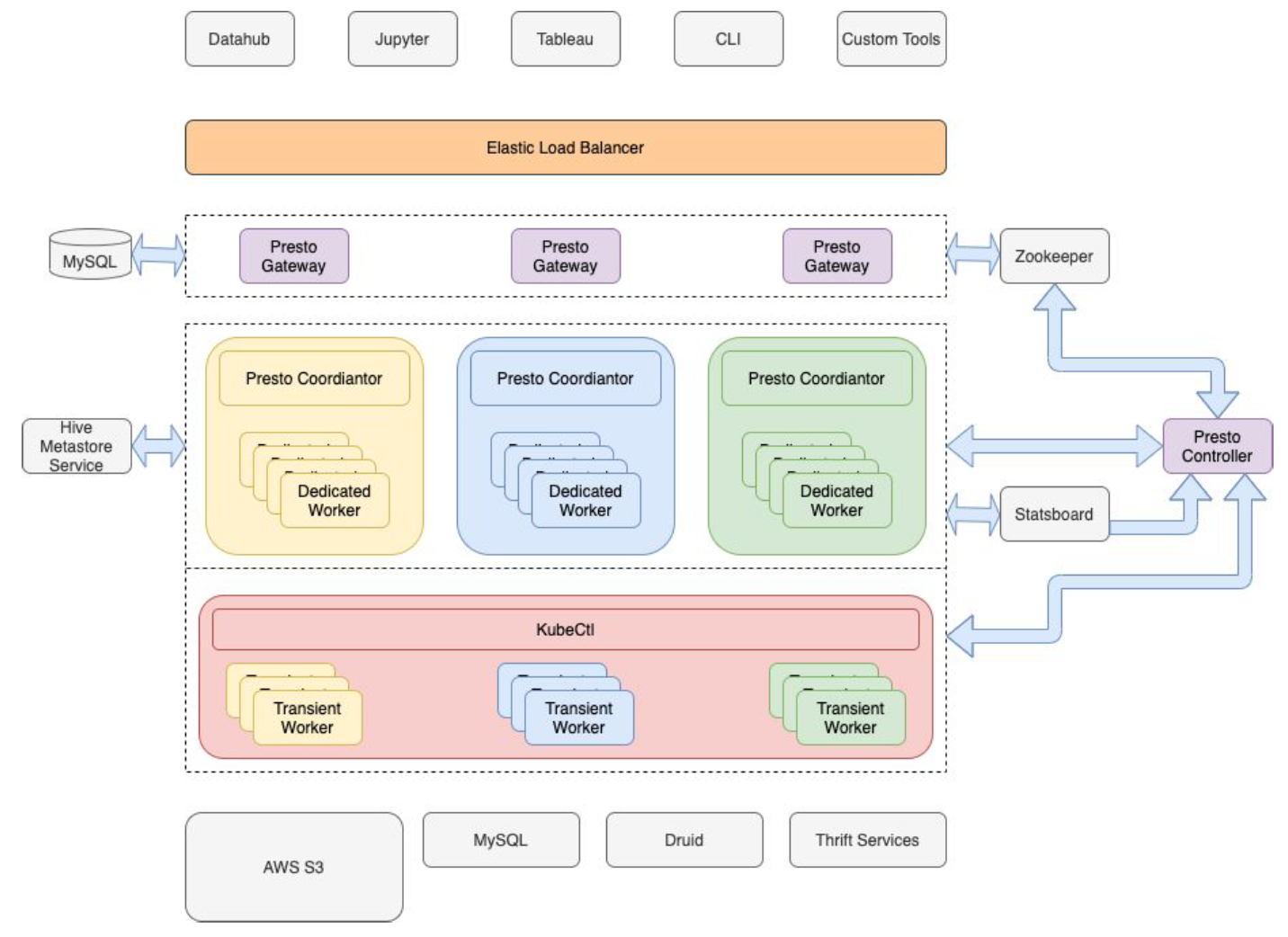
作为一家数据驱动型公司,Pinterest 的许多关键商业决策都是基于数据分析做出的。分析平台是由大数据平台团队提供的,它使公司内部的其他人能够处理 PB 级的数据,以得到他们需要的结果。数据分析是 Pinterest 的一个关键功能,不仅可以回答商业问题,还可以解决工程问题,对功能进行优先排序,识别用户面临的最常见问题, w397090770 4年前 (2021-06-20) 656℃ 0评论0喜欢
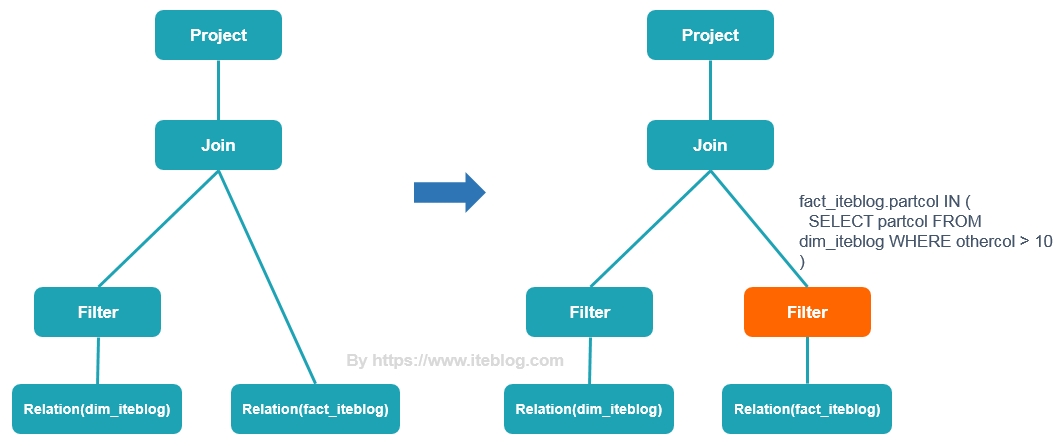
早在2005年,Oracle 数据库就支持比较丰富的 dynamic filtering 功能,而 Spark 和 Presto 在最近版本才开始支持这个功能。本文将介绍 Presto 动态过滤的原理以及具体使用。Apache Spark 的动态分区裁减Apache Spark 3.0 给我们带来了许多的新特性用于加速查询性能,其中一个就是动态分区裁减(Dynamic Partition Pruning,DPP),所谓的动态分区裁剪就 w397090770 4年前 (2021-06-01) 1505℃ 0评论2喜欢
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 4年前 (2021-03-05) 1085℃ 0评论6喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num w397090770 4年前 (2021-02-20) 1202℃ 0评论4喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 w397090770 4年前 (2021-01-21) 560℃ 0评论2喜欢
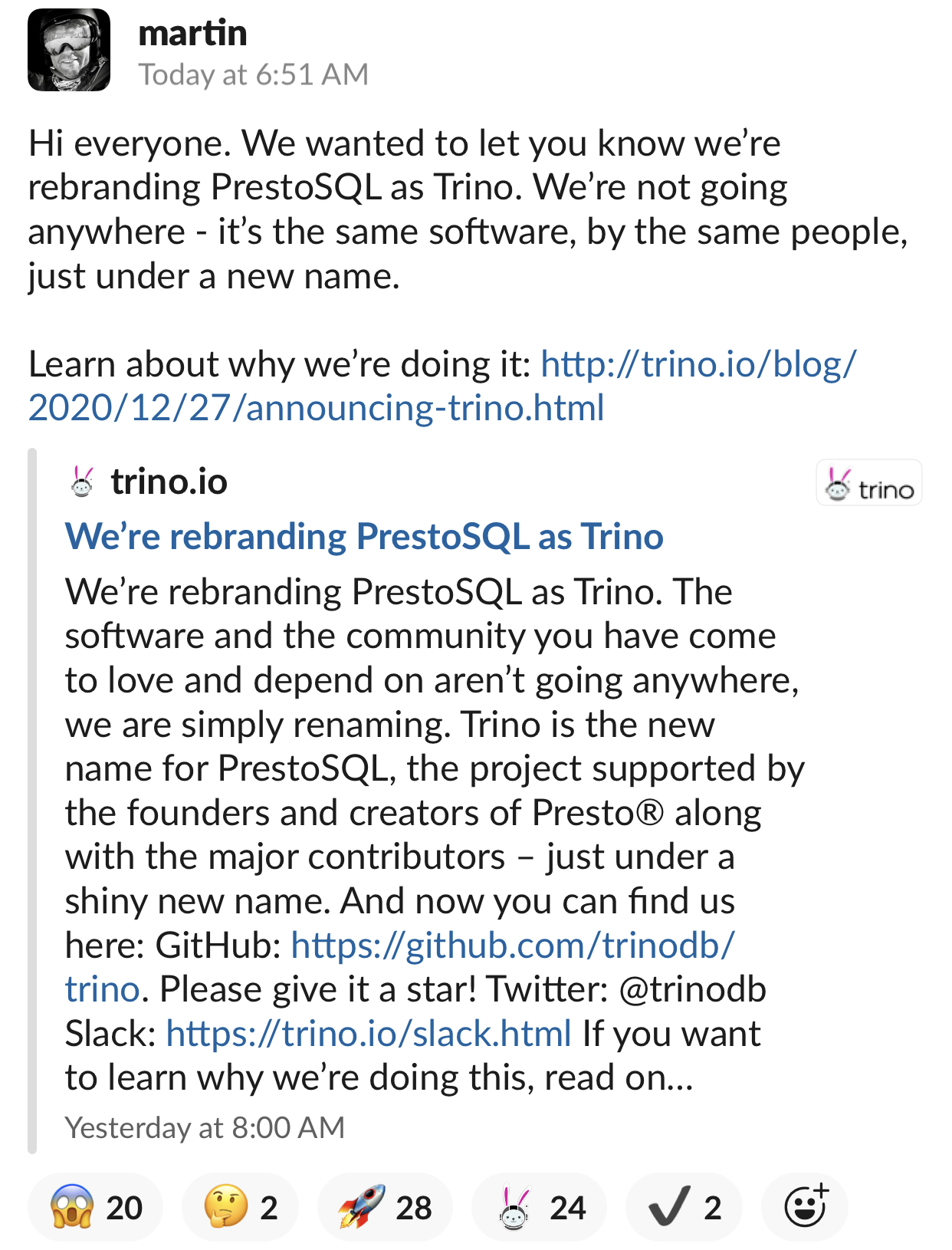
2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 4年前 (2020-12-28) 2062℃ 0评论1喜欢
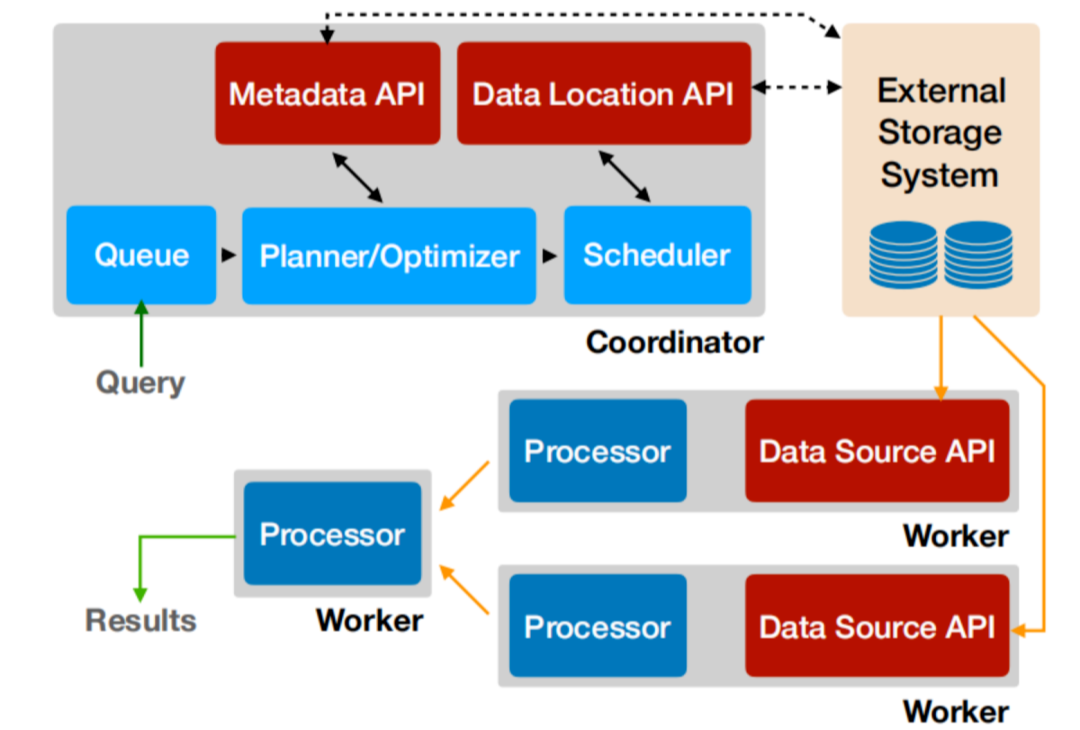
本文作者:车好多大数据 OLAP 团队-王培,由车好多大数据 OLAP 团队相关同事投稿。Presto 简介简介Presto 最初是由 Facebook 开发的一个分布式 SQL 执行引擎, 它被设计为用来专门进行高速、实时的数据分析,以弥补 Hive 在速度和对接多种数据源上的短板。发展历史如下:2012年秋季,Facebook启动Presto项目2013年冬季,Presto开源 w397090770 4年前 (2020-12-21) 984℃ 0评论3喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 845℃ 0评论2喜欢
Presto在滴滴内部发展三年,已经成为滴滴内部Ad-Hoc和Hive SQL加速的首选引擎。目前服务6K+用户,每天读取2PB ~ 3PB HDFS数据,处理30万亿~35万亿条记录,为了承接业务及丰富使用场景,滴滴Presto需要解决稳定性、易用性、性能、成本等诸多问题。我们在3年多的时间里,做了大量优化和二次开发,积攒了非常丰富的经验。本文分享了滴滴 w397090770 5年前 (2020-10-21) 1335℃ 0评论4喜欢
前言Facebook 的数据仓库构建在 HDFS 集群之上。在很早之前,为了能够方便分析存储在 Hadoop 上的数据,Facebook 开发了 Hive 系统,使得科学家和分析师可以使用 SQL 来方便的进行数据分析,但是 Hive 使用的是 MapReduce 作为底层的计算框架,随着数据分析的场景和数据量越来越大,Hive 的分析速度越来越慢,可能得花费数小时才能完成 w397090770 5年前 (2020-08-09) 1681℃ 0评论4喜欢