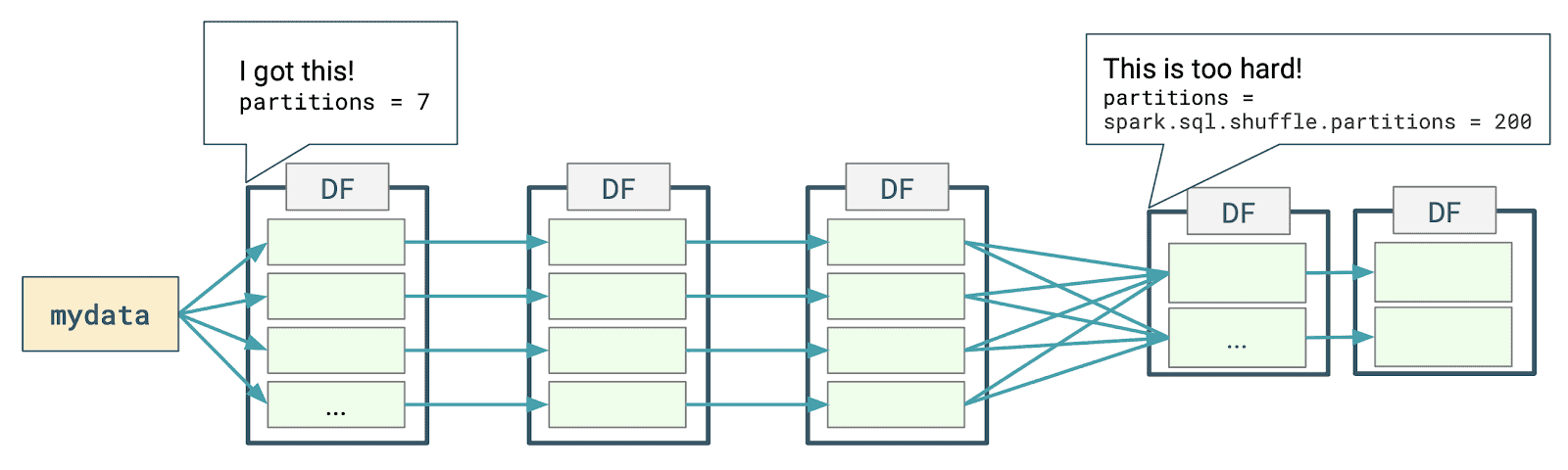
随着 Spark >= 3.3(在 3.4 中更加成熟)中引入的存储分区连接(Storage Partition Join,SPJ)优化技术,您可以在不触发 Shuffle 的情况下对分区的数据源 V2 表执行连接操作(当然,需要满足一些条件)。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Shuffle 是昂贵的,尤其是在 Spark 中的连 w397090770 3周前 (01-03) 96℃ 0评论0喜欢
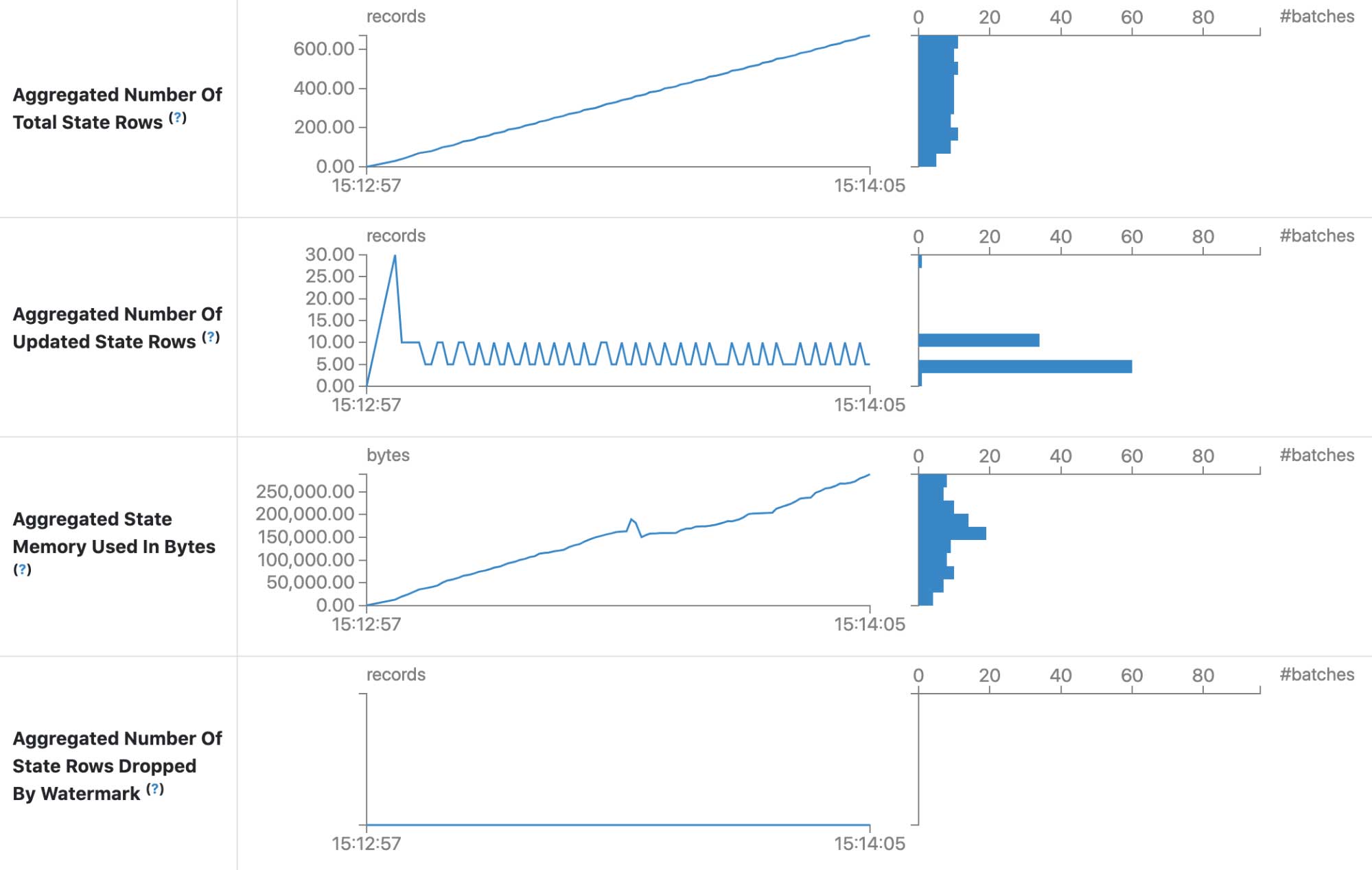
本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:降低延迟并改进有状态流处理;提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;改进资源分配和可伸缩性。下面我们来简单地看下这些目标。目标一: w397090770 3年前 (2022-02-23) 874℃ 0评论6喜欢
本文来自 Kyligence 主办的 Data & AI Meetup(第二期),会议时间为 11月16日。本期会议特别邀请了 Spark 社区大佬范文臣带来 Spark 3.2.0 新特性的首发解读。范文臣,Databricks 开源组技术主管,Apache Spark PMC member,Spark 社区最活跃的贡献者之一,目前主要负责 Spark Core/SQL 的设计开发和开源社区管理。Spark 作为目前大数据领域使用最普及的 w397090770 3年前 (2021-11-30) 687℃ 0评论0喜欢
在 LinkedIn,我们非常依赖离线数据分析来进行数据驱动的决策。多年来,Apache Spark 已经成为 LinkedIn 的主要计算引擎,以满足这些数据需求。凭借其独特的功能,Spark 为 LinkedIn 的许多关键业务提供支持,包括数据仓库、数据科学、AI/ML、A/B 测试和指标报告。需要大规模数据分析的用例数量也在快速增长。从 2017 年到现在,LinkedIn 的 S w397090770 3年前 (2021-09-08) 1065℃ 0评论4喜欢
在几乎所有处理复杂数据的领域,Spark 已经迅速成为数据和分析生命周期团队的事实上的分布式计算框架。Spark 3.0 最受期待的特性之一是新的自适应查询执行框架(Adaptive Query Execution,AQE),该框架解决了许多 Spark SQL 工作负载遇到的问题。AQE 在2018年初由英特尔和百度组成的团队最早实现。AQE 最初是在 Spark 2.4 中引入的, Spark 3.0 做 w397090770 4年前 (2021-05-23) 1225℃ 0评论2喜欢
Apache Spark 3.1.x 版本发布到现在已经过了两个多月了,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming更多详情请参见这里。在这篇博文中,我们总结了3.1版本中 w397090770 4年前 (2021-05-16) 785℃ 0评论3喜欢
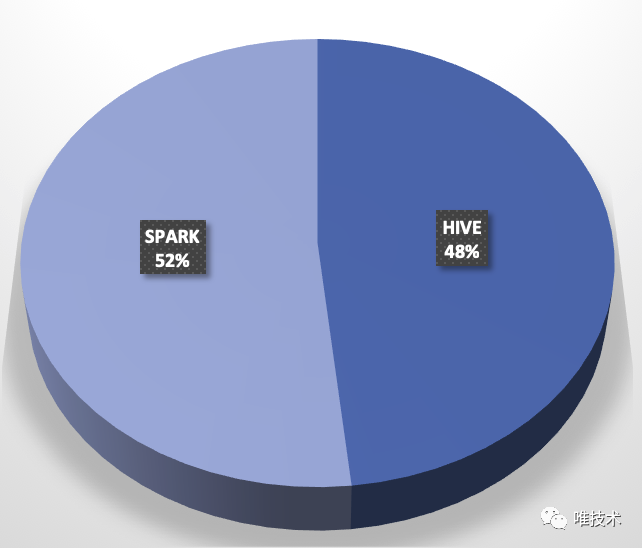
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1331℃ 0评论4喜欢
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 4年前 (2021-03-03) 2346℃ 0评论10喜欢
Spark 3.0 为我们带来了许多令人期待的特性。动态分区裁剪(dynamic partition pruning)就是其中之一。本文将通过图文的形式来带大家理解什么是动态分区裁剪。Spark 中的静态分区裁剪在介绍动态分区裁剪之前,有必要对 Spark 中的静态分区裁剪进行介绍。在标准数据库术语中,裁剪意味着优化器将避免读取不包含我们正在查找的数 w397090770 4年前 (2021-01-06) 1307℃ 0评论5喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 4年前 (2020-11-24) 1182℃ 0评论4喜欢