NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 788℃ 0评论2喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2428℃ 0评论8喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。如果大家想 w397090770 6年前 (2019-11-08) 2087℃ 0评论6喜欢
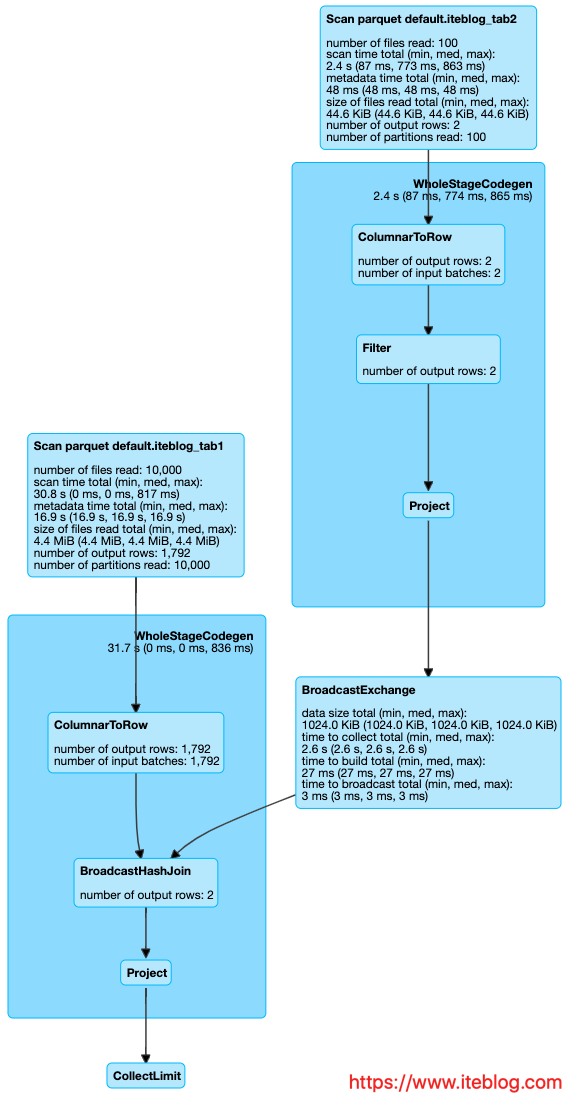
我在 这篇 文章中介绍了 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning),里面涉及到动态分区的优化思路等,但是并没有涉及到如何使用,本文将介绍在什么情况下会启用动态分区裁剪。并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这 w397090770 6年前 (2019-11-08) 2421℃ 0评论3喜欢
静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 6年前 (2019-11-04) 2733℃ 0评论6喜欢
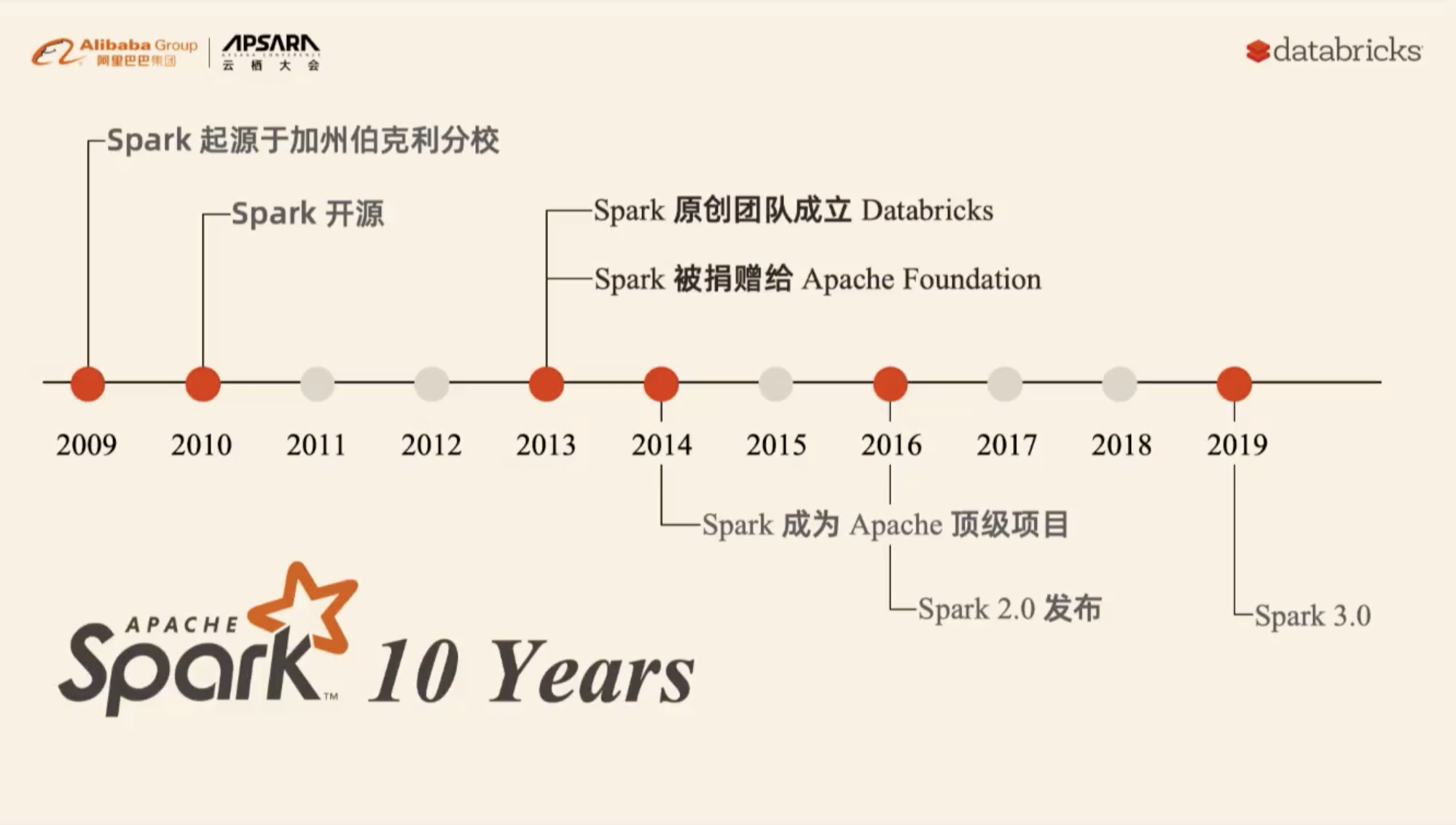
本资料来自2019-09-26在杭州举办的云栖大会的大数据 & AI 峰会分会。议题名称《New Developments in the Open Source Ecosystem: Apache Spark 3.0 and Koalas》,分享嘉宾李潇,Databricks Spark 研发总监。下面是本次会议的视频(由于微信公众号的限制,只能发布小于30分钟的视频,完整视频和 PPT 请关注 过往记忆大数据 公众号并回复 spark_yq 获取。) w397090770 6年前 (2019-09-27) 2951℃ 0评论3喜欢
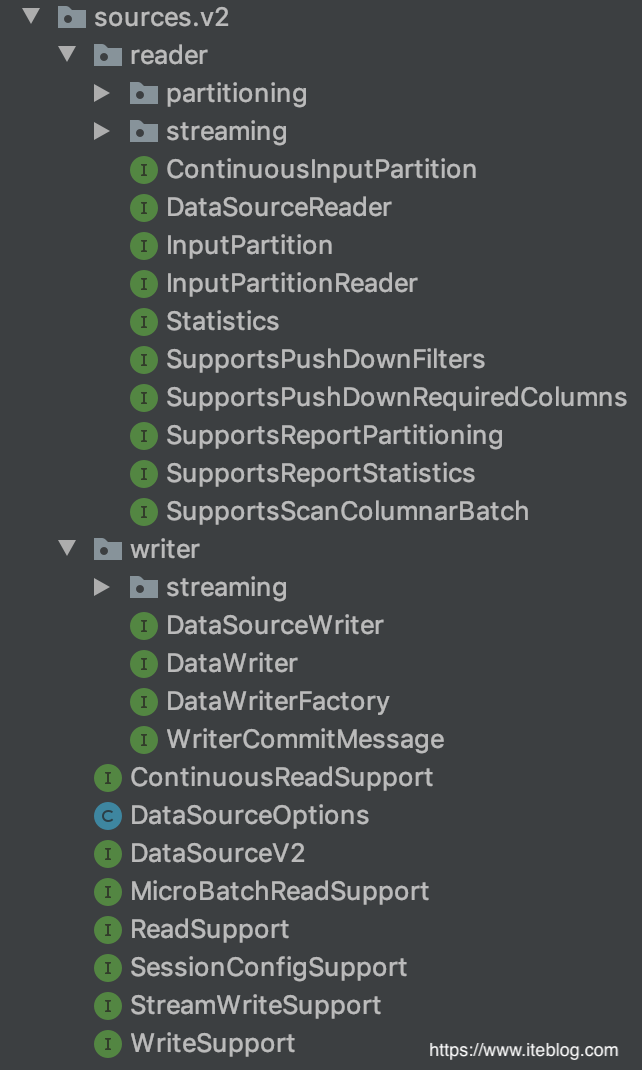
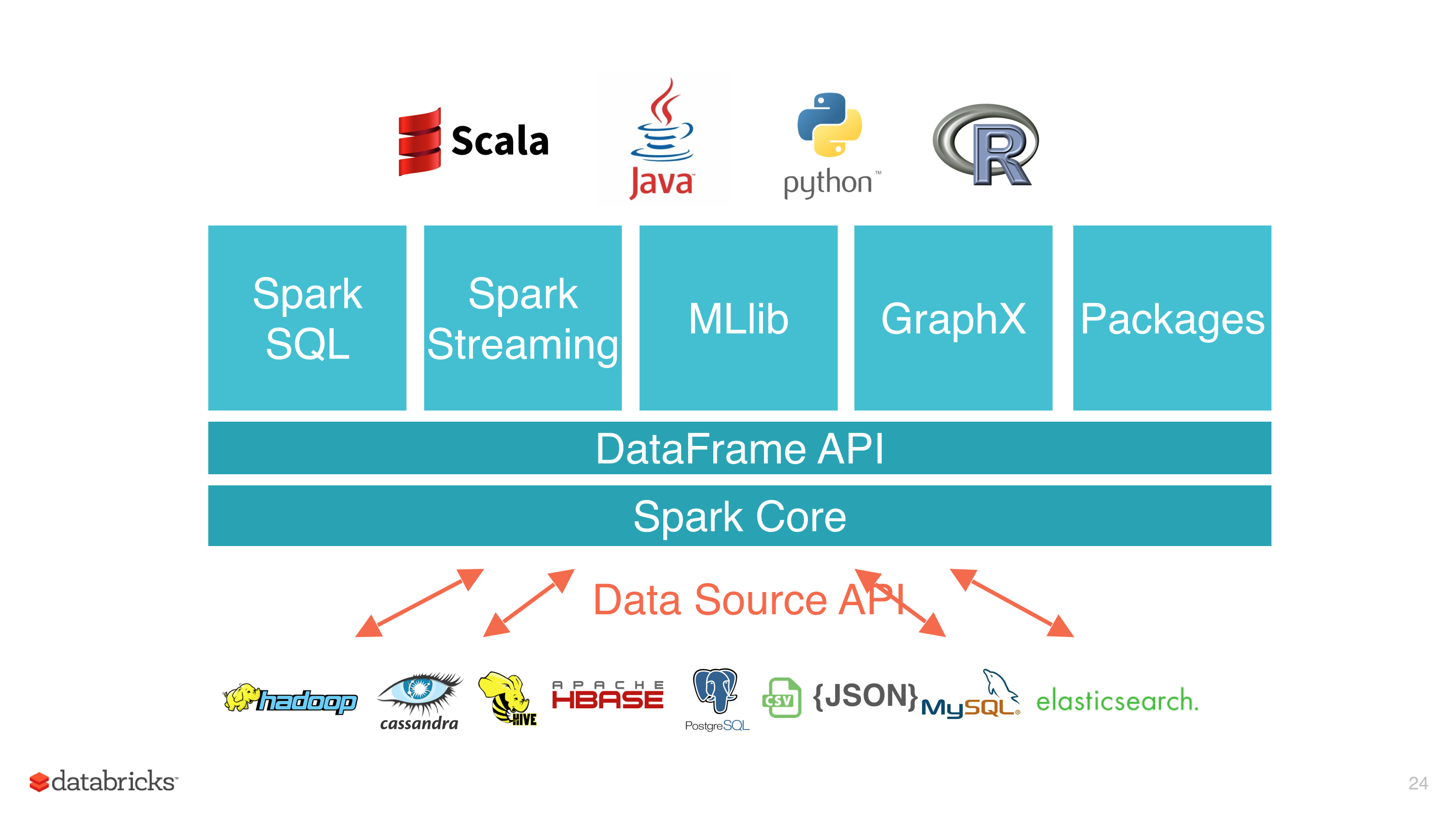
我们在 Apache Spark DataSource V2 介绍及入门编程指南(上) 文章中介绍了 Apache Spark DataSource V1 的不足,所以才有了 Data Source API V2 的诞生。Data Source API V2为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Source API V2,在保留原有的功能之外,还解决了 Data Source API V1 存在的一些问题,比如不再依赖上层 API w397090770 6年前 (2019-08-13) 4099℃ 1评论9喜欢
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了 D w397090770 6年前 (2019-08-13) 3656℃ 0评论3喜欢
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自 Databricks、NVIDIA、Google 以及阿里巴巴的工程师们正在为 Apache Spark 添加 w397090770 6年前 (2019-03-10) 6507℃ 0评论9喜欢