本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:降低延迟并改进有状态流处理;提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;改进资源分配和可伸缩性。下面我们来简单地看下这些目标。目标一: w397090770 3年前 (2022-02-23) 874℃ 0评论6喜欢
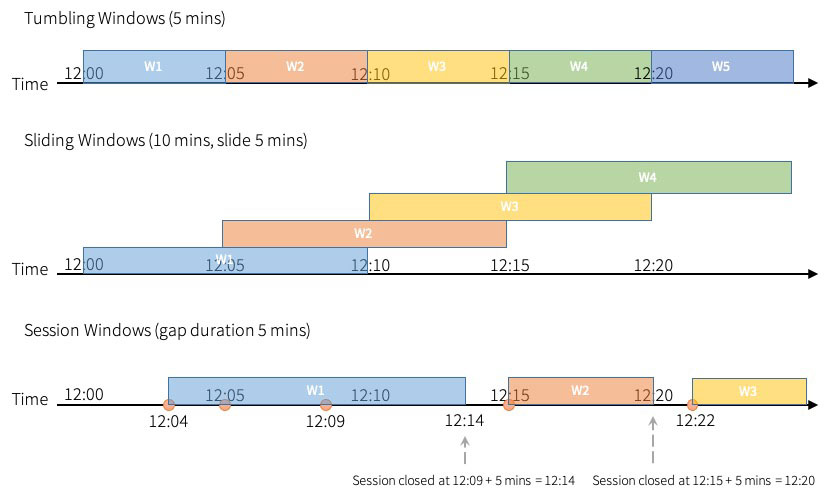
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had w397090770 3年前 (2021-10-21) 879℃ 0评论0喜欢
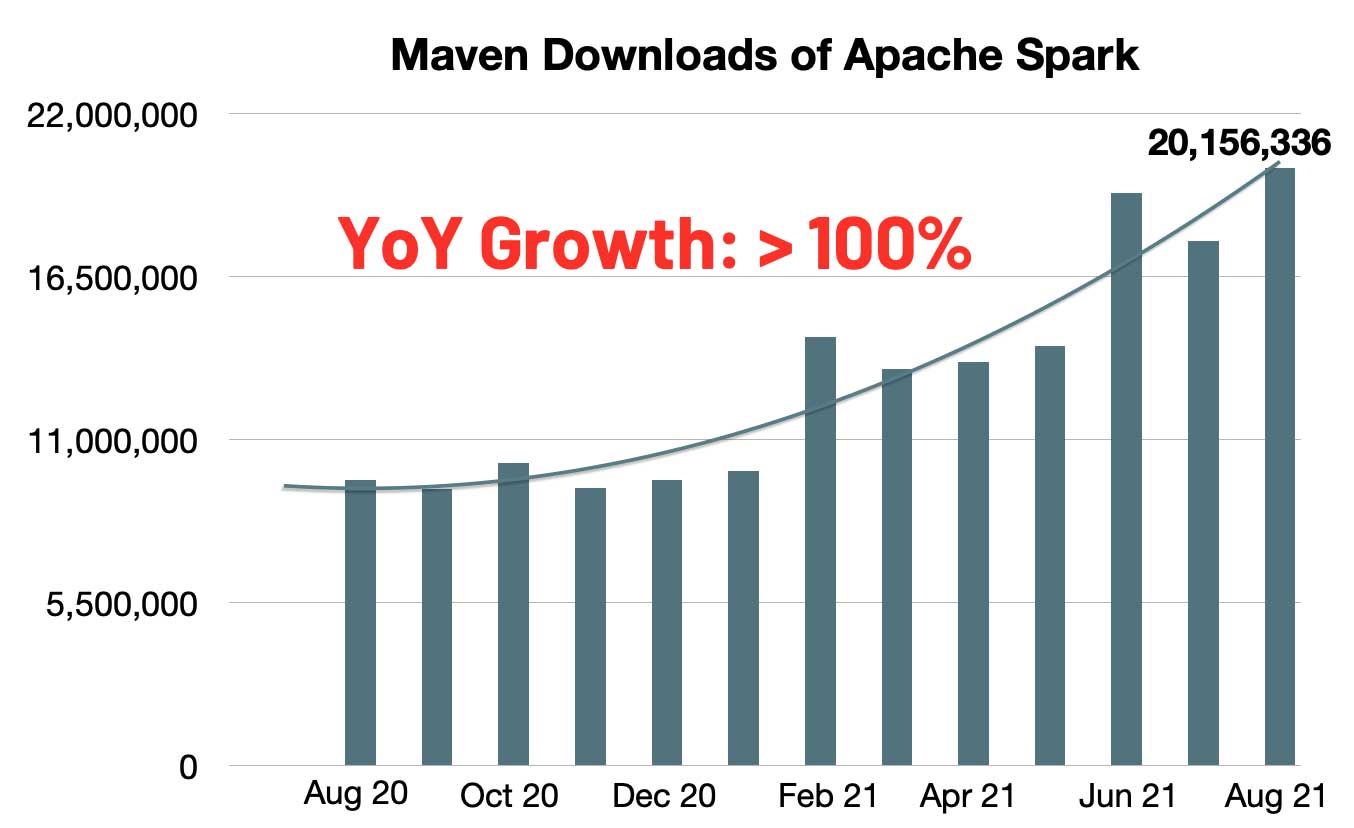
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 w397090770 3年前 (2021-10-20) 1377℃ 0评论3喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 866℃ 0评论3喜欢