本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:降低延迟并改进有状态流处理;提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;改进资源分配和可伸缩性。下面我们来简单地看下这些目标。目标一: w397090770 3年前 (2022-02-23) 874℃ 0评论6喜欢
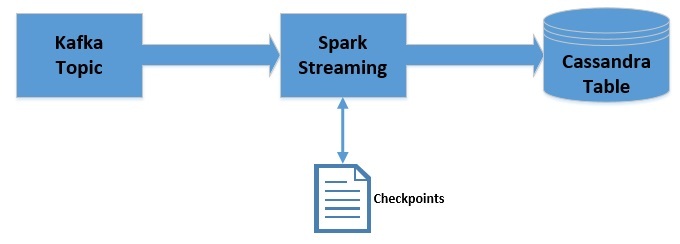
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4076℃ 0评论8喜欢
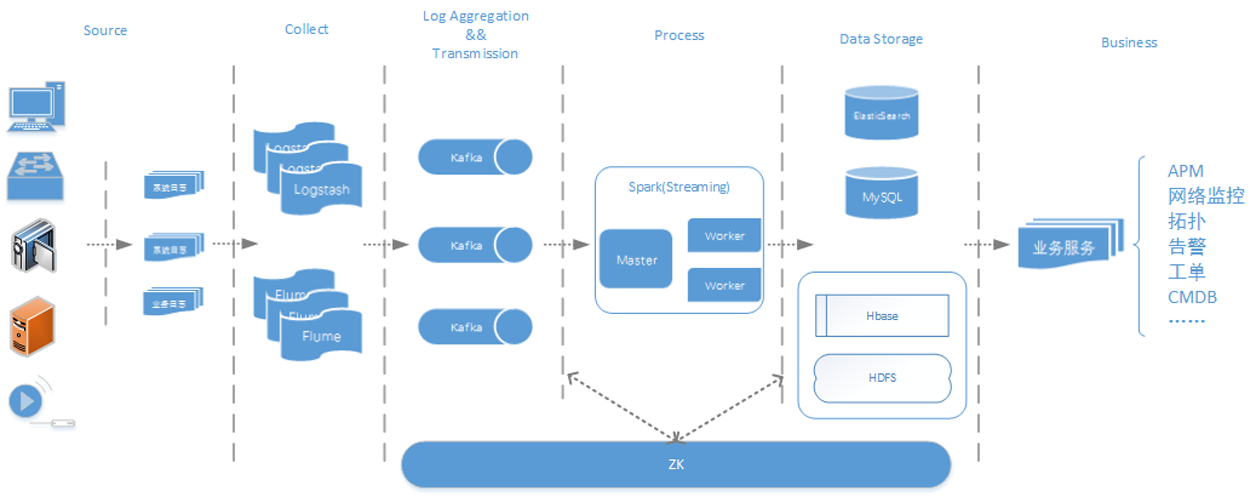
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 8年前 (2017-01-01) 11298℃ 1评论39喜欢
Spark Streaming除了可以使用内置的接收器(Receivers,比如Flume、Kafka、Kinesis、files和sockets等)来接收流数据,还可以自定义接收器来从任意的流中接收数据。开发者们可以自己实现org.apache.spark.streaming.receiver.Receiver类来从其他的数据源中接收数据。本文将介绍如何实现自定义接收器,并且在Spark Streaming应用程序中使用。我们可以用S w397090770 9年前 (2016-03-03) 5968℃ 2评论4喜欢
第二期上海大数据流处理(Shanghai Big Data Streaming 2nd Meetup)于2015年12月6日下午12:45在上海世贸大厦22层英特尔(中国)有限公司延安西路2299号进行,分享的主题如下:一、演讲者1/Speaker 1: 张天伦 英特尔大数据组软件工程师 个人介绍/BIO: 英特尔开源流处理系统Gearpump开发者,长期关注大数据领域和分布式计算,专注于流处理 w397090770 9年前 (2015-12-16) 3678℃ 0评论5喜欢