Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始,Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro Data Source for Apache Spark。除此之外,它还提供以下功能:新函数 from_avro() 和 to_avro() w397090770 6年前 (2018-12-11) 3153℃ 0评论9喜欢
Apache Spark 2.4 新增了24个内置函数和5个高阶函数,本文将对这29个函数的使用进行介绍。关于 Apache Spark 2.4 的新特性,可以参见 《Apache Spark 2.4 正式发布,重要功能详细介绍》。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop针对数组类型的函数array_distinctarray_distinct(array<T>): array<T w397090770 6年前 (2018-11-25) 7528℃ 0评论18喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 6年前 (2018-11-22) 3314℃ 1评论10喜欢
Apache Spark 2.4 是在11月08日正式发布的,其带来了很多新的特性具体可以参见这里,本文主要介绍这次为复杂数据类型新引入的内置函数和高阶函数。本次 Spark 发布共引入了29个新的内置函数来处理复杂类型(例如,数组类型),包括高阶函数。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop w397090770 6年前 (2018-11-21) 2486℃ 0评论2喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); w397090770 6年前 (2018-11-10) 4539℃ 0评论6喜欢
Apache Spark 2.4 与昨天正式发布,Apache Spark 2.4 版本是 2.x 系列的第五个版本。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Spark 2.4 为我们带来了众多的主要功能和增强功能,主要如下:新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中 w397090770 6年前 (2018-11-09) 3358℃ 0评论1喜欢
最近突然收到线上服务器发出来的磁盘满了的报警,然后到服务器上发现 Apache Spark 的历史服务器(HistoryServer)日志居然占了近 500GB,如下所示:[code lang="bash"][root@iteblog.com spark]# ll -htotal 328-rw-rw-r-- 1 spark spark 15.4G Jul 11 13:09 spark-spark-org.apache.spark.deploy.history.HistoryServer-1-iteblog.com.out-rw-rw-r-- 1 spark spark 369M May 30 09:07 spark-spark-org.a w397090770 6年前 (2018-10-29) 2222℃ 0评论2喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 6年前 (2018-10-13) 3491℃ 1评论8喜欢
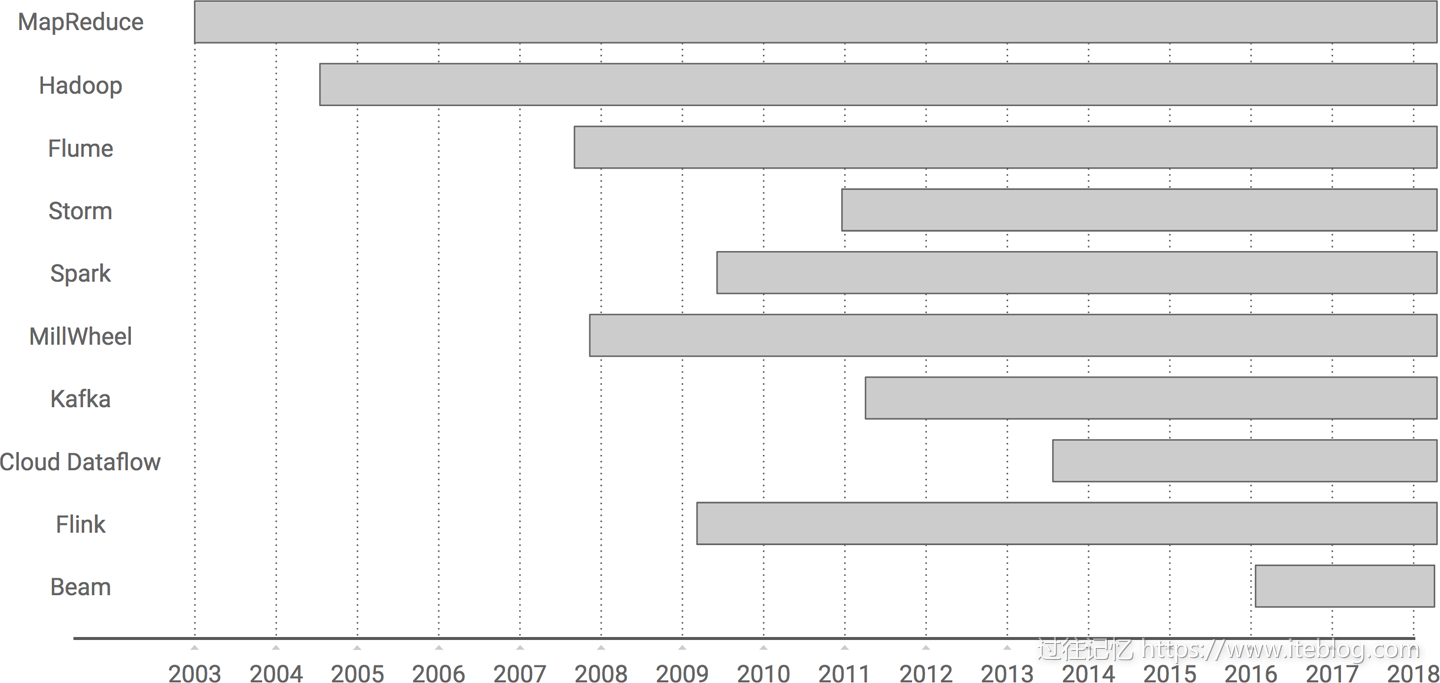
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10293℃ 2评论27喜欢
为帮助开发者更深入的了解这三个大数据开源技术及其实际应用场景,9月8日,InfoQ联合华为云举办了一场实时大数据Meetup,集结了来自Databricks、华为及美团点评的大咖级嘉宾前来分享。作为Spark Structured Streaming最核心的开发人员、Databricks工程师,Tathagata Das(以下简称“TD”)在开场演讲中介绍了Structured Streaming的基本概念 w397090770 6年前 (2018-09-21) 4817℃ 0评论10喜欢



![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)