为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 7年前 (2018-10-13) 3532℃ 1评论8喜欢
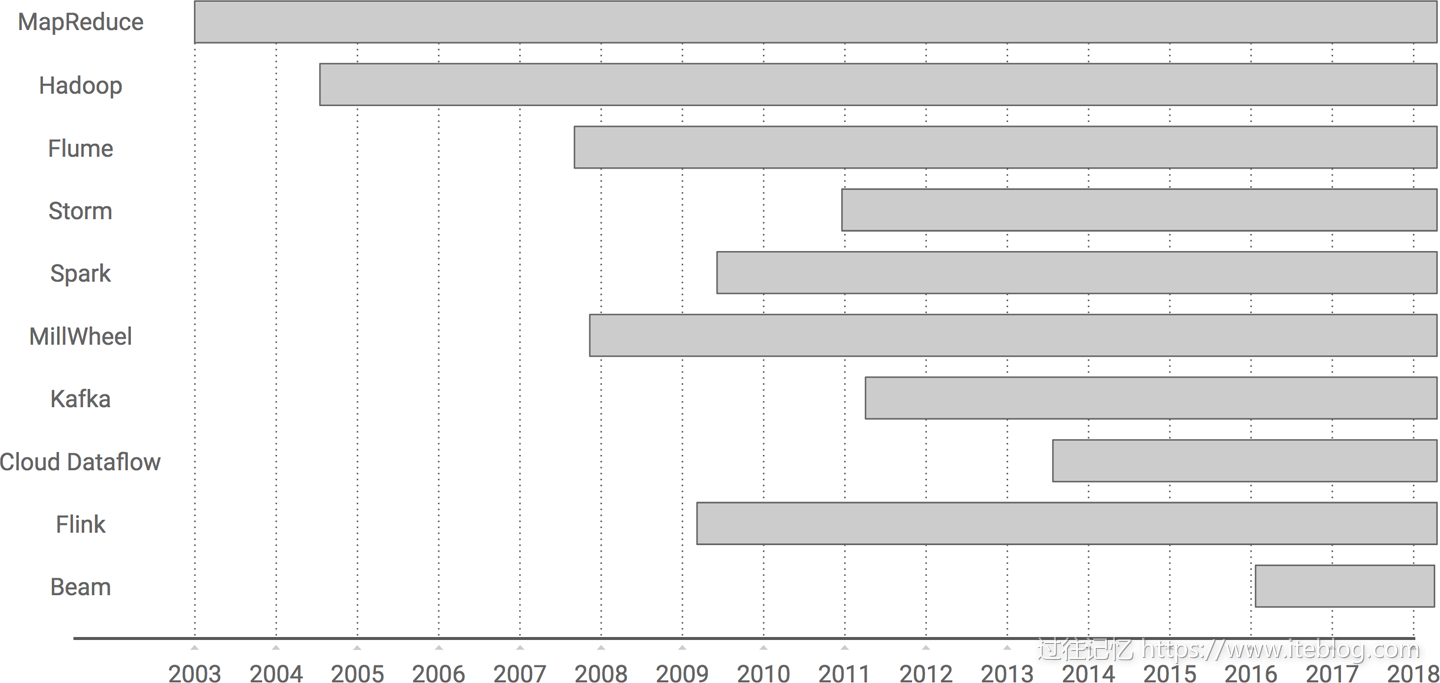
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 7年前 (2018-10-08) 10393℃ 2评论27喜欢
为帮助开发者更深入的了解这三个大数据开源技术及其实际应用场景,9月8日,InfoQ联合华为云举办了一场实时大数据Meetup,集结了来自Databricks、华为及美团点评的大咖级嘉宾前来分享。作为Spark Structured Streaming最核心的开发人员、Databricks工程师,Tathagata Das(以下简称“TD”)在开场演讲中介绍了Structured Streaming的基本概念 w397090770 7年前 (2018-09-21) 4834℃ 0评论10喜欢
本文来自于2018年09月19日在 Adobe Systems Inc 举行的 Apache Spark Meetup。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop即将发布的 Apache Spark 2.4 版本是 2.x 系列的第五个版本。 本文对 Apache Spark 2.4 的主要功能和增强功能进行了概述。新的调度模型(Barrier Scheduling),使用户能够将分布式深度学 w397090770 7年前 (2018-09-20) 3301℃ 0评论8喜欢
经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取 Kafka 中的数据,这种情况下 Spark RDD 中分区和 Kafka 分区是一一对 w397090770 7年前 (2018-09-08) 6649℃ 0评论25喜欢
!! expr :逻辑非。%expr1 % expr2 - 返回 expr1/expr2 的余数.例子:[code lang="sql"]> SELECT 2 % 1.8; 0.2> SELECT MOD(2, 1.8); 0.2[/code]&expr1 & expr2 - 返回 expr1 和 expr2 的按位AND的结果。例子:[code lang="sql"]> SELECT 3 & 5; 1[/code]*expr1 * expr2 - 返回 expr1*expr2.例子:[code lang="sql"]> SELECT 2 * 3; 6[/code]+ w397090770 7年前 (2018-07-13) 16667℃ 0评论2喜欢
为期三天的 Spark Summit 在美国时间 2018-06-04 ~ 06-06 于旧金山的 Moscone Center 举行,不少人已经注意到,今年的会议已经更名为 Spark+AI, 去年 12 月份时,Databricks 在他们的博客中就已经提到过,2018 年的会议将包括更多人工智能的内容,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark Summit 2018 吸引了全球近 200 w397090770 7年前 (2018-06-18) 3679℃ 0评论14喜欢
背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 7年前 (2018-05-28) 27404℃ 409评论62喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 7年前 (2018-05-13) 3946℃ 1评论8喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19938℃ 4评论93喜欢

![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)



![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png)

