通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的用例来了解有关Spark中的各种客户端API编码。然后,您将学习到各 w397090770 8年前 (2017-02-12) 3113℃ 0评论6喜欢
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程 w397090770 8年前 (2017-02-11) 1547℃ 0评论1喜欢
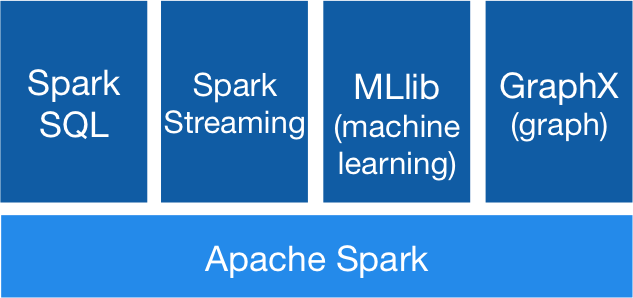
Spark已经成为数据科学专业人士最有前途的大数据分析引擎。Apache Spark真正的力量和价值在于它能够以高速和准确的方式执行数据科学任务;Spark的卖点是它结合ETL,批处理分析,实时流分析,机器学习,图形处理和可视化;它允许您轻松处理非结构化的原始数据集。 本书将让您舒适和自信地使用Spark完成数据科学任务。 w397090770 8年前 (2017-02-10) 2239℃ 0评论6喜欢
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也非常适合对时实的流数据进行处理。 Spark目前已经 w397090770 8年前 (2017-02-06) 1684℃ 0评论4喜欢
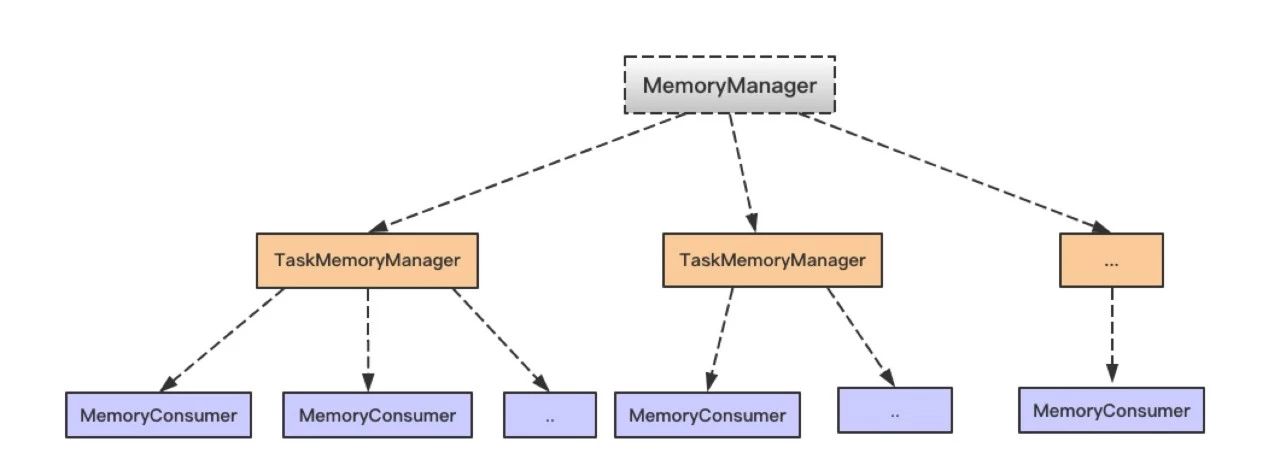
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 8年前 (2017-01-17) 823℃ 0评论1喜欢
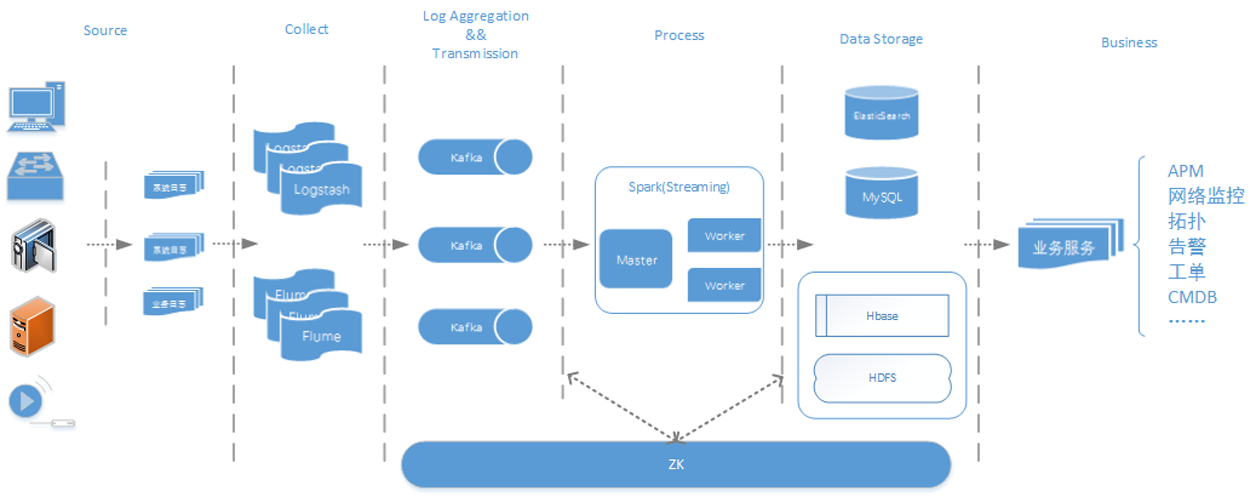
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 8年前 (2017-01-01) 11285℃ 1评论39喜欢
Apache Spark 2.1.0是 2.x 版本线的第二个发行版。此发行版在为Structured Streaming进入生产环境做出了重大突破,Structured Streaming现在支持了event time watermarks了,并且支持Kafka 0.10。此外,此版本更侧重于可用性,稳定性和优雅(polish),并解决了1200多个tickets。以下是本版本的更新:Core and Spark SQL Spark官方发布新版本时,一般 w397090770 8年前 (2016-12-30) 4246℃ 0评论8喜欢
本书介绍了如何使用 Spark Streaming 开发应用程序已经一些最佳实践。适合数据科学家、大数据专家、BI分析以及数据架构师阅读。全书名称:Pro Spark Streaming The Zen of Real-Time Analytics Using Apache Spark,作者Nabi, Zubair,由Apress于2016-07-01出版,全书共231页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog zz~~ 8年前 (2016-12-18) 4588℃ 0评论6喜欢
本书是《Spark快速数据处理》第三版,全书基于Spark 2.0.0编写。本书适合Spark入门者,作者Krishna Sankar,由Packt出版社于2016年10月出版,全书共274页。通过本书你将学到以下知识: (1)、安装和设置你的Spark集群; (2)、使用Spark交互式Shell来实现简单的分布式应用程序; (3)、使用新的DataFrame API操作数据; w397090770 8年前 (2016-12-14) 4408℃ 0评论5喜欢
本书旨在通过教你如何扩展Spark的功能,将你对Spark的有限知识提升到一个新的水平。全书从Spark生态系统开始概述,您将学习如何使用MLlib创建一个完全的神经网络系统,然后您将了解如何调整流处理以获得最佳性能并确保并行处理。本书作者Mike Frampton,由Packt 于2015年09月出版,全书318页,通过本书你将学到以下知识: ( w397090770 8年前 (2016-12-04) 3845℃ 0评论9喜欢

![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)
![Spark Summit East 2017部分PPT下载[共18个]](https://www.iteblog.com/pic/iteblog.png)
![[电子书]Apache Spark for Data Science Cookbook PDF下载](https://www.iteblog.com/pic/books/Spark_for_Data_Science_Cookbook_iteblog.jpg)

![[电子书]Pro Spark Streaming pdf电子书下载](https://www.iteblog.com/pic/Pro_Spark_Streaming.jpg)
![[电子书]Fast Data Processing with Spark 2, 3rd Edition下载](https://www.iteblog.com/pic/books/Fast_Data_Processing_with_Spark_2_iteblog.jpg)
![[电子书]Mastering Apache Spark下载](https://www.iteblog.com/pic/books/Mastering_Apache_Spark.jpg)