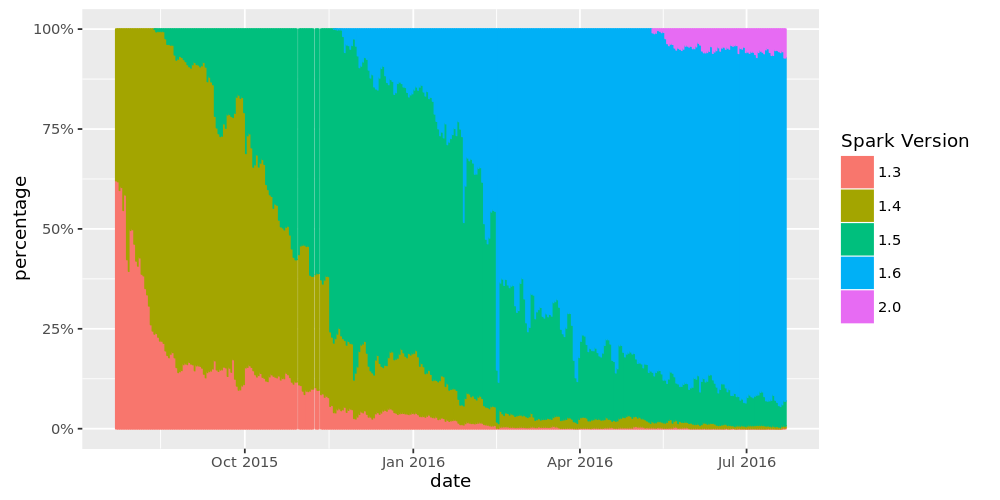
Streaming job 的调度与执行 我们先来看看如下 job 调度执行流程图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么很难保证 exactly once 上面这张流程图最主要想说明的就是,job 的提交执行是异步的,与 checkpoint 操作并不是原子操作。这样的机制会引起数据重复消费问题: zz~~ 8年前 (2016-09-08) 8890℃ 5评论12喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 8年前 (2016-08-31) 3338℃ 0评论5喜欢
Apache Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。 本文我们将介绍在Spark 2.0中如何使用SparkSession。更多关于SparkSession的文章请参见: w397090770 8年前 (2016-08-24) 15171℃ 2评论11喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 w397090770 8年前 (2016-08-10) 36831℃ 2评论73喜欢
Apache Spark 2.0发布信息可以参见《Apache Spark 2.0.0正式发布及其功能介绍》 我们很荣幸地宣布,自7月26日起Databricks开始提供Apache Spark 2.0的下载,这个版本是基于社区在过去两年的经验总结而成,不但加入了用户喜爱的功能,也修复了之前的痛点。 本文总结了Spark 2.0的三大主题:更简单、更快速、更智能,另有Spark w397090770 8年前 (2016-07-28) 14404℃ 0评论28喜欢
《Apache Spark 2.0重大功能介绍》:/archives/1721 《Apache Spark作为编译器:深入介绍新的Tungsten执行引擎》:/archives/1679 《Spark 2.0技术预览:更容易、更快速、更智能》:/archives/1668 Apache Spark 2.0.0于2016-07-27正式发布。它是2.x版本线上的第一个版本。主要的更新是API可用性,SQL 2003的支持,性能提升,structured streaming w397090770 8年前 (2016-07-27) 7623℃ 4评论7喜欢
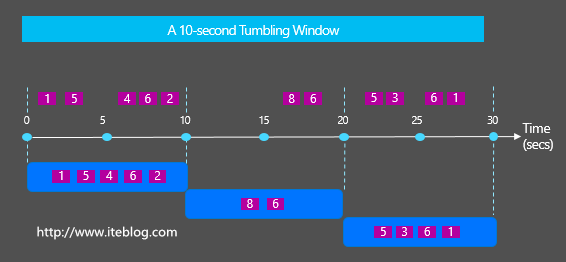
在流系统中通常会经常使用到Windows来统计一定范围的数据,比如按照固定时间、按个数等统计。一般会存在两种类型的Windows:Tumbling Windows vs Sliding Windows,它们很容易被初学者混淆,那么Tumbling Windows vs Sliding Windows之间到底有啥区别与联系呢?这就是本文将要展开的。 Tumbling的中文意思是摔跤,翻跟头,翻筋斗;Sliding中 w397090770 8年前 (2016-07-26) 3471℃ 0评论4喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 8年前 (2016-07-26) 10920℃ 3评论17喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 8年前 (2016-07-25) 216099℃ 0评论844喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列的介 w397090770 8年前 (2016-07-14) 7607℃ 2评论4喜欢