如果你的Driver内存容量不能容纳一个大型RDD里面的所有数据,那么不要做以下操作:[code lang="scala"]val values = iteblogVeryLargeRDD.collect()[/code] Collect 操作会试图将 RDD 里面的每一条数据复制到Driver上,如果你Driver端的内存无法装下这些数据,这时候会发生内存溢出和崩溃。 相反,你可以调用take或者 takeSample来限制数 w397090770 10年前 (2015-05-20) 3163℃ 0评论4喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 10年前 (2015-05-20) 8179℃ 0评论7喜欢
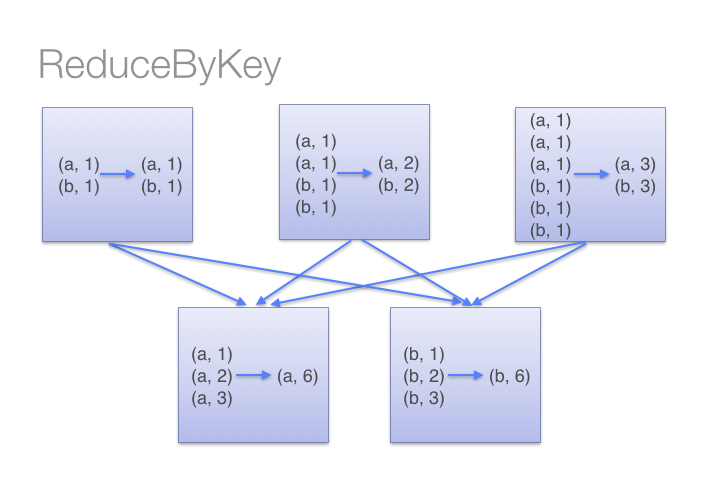
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 10年前 (2015-05-18) 33628℃ 0评论51喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-05-15) 4830℃ 0评论3喜欢
如果你想知道Hadoop作业运行日志,可以查看这里《Hadoop日志存放路径详解》 在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。 Spark日志确切的存放路径和部署模式相关: (1)、如果是Spark Standalone模式,我们可以直接在Master UI界 w397090770 10年前 (2015-05-14) 39783℃ 6评论16喜欢
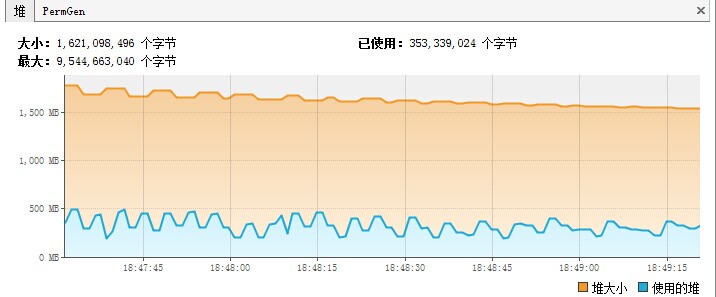
jvisualvm工具JDK自带的一个监控工具,该工具是用来监控java运行程序的cpu、内存、线程等的使用情况,并且使用图表的方式监控java程序、还具有远程监控能力,不失为一个用来监控Java程序的好工具。 同样,我们可以使用jvisualvm来监控Spark应用程序(Application),从而可以看到Spark应用程序堆,线程的使用情况,从而根据这 w397090770 10年前 (2015-05-13) 10732℃ 0评论9喜欢
在本博客的《Spark Metrics配置详解》文章中介绍了Spark Metrics的配置,其中我们就介绍了Spark监控支持Ganglia Sink。Ganglia是UC Berkeley发起的一个开源集群监视项目,主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性 w397090770 10年前 (2015-05-11) 13968℃ 1评论13喜欢
在提交作业的时候出现了以下的异常信息:[code lang="scala"]2015-05-05 11:09:28,071 INFO [Driver] - Attempting to load checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-14307949860002015-05-05 11:09:28,076 WARN [Driver] - Error reading checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-1430794986000java.io.InvalidClassException: org.apache.spark.streaming w397090770 10年前 (2015-05-10) 18821℃ 0评论7喜欢
在几年前,Oracle宣布不再维护Java 6的更新(看这里http://www.computerworld.com/article/2494112/application-security/oracle-to-stop-patching-java-6-in-february-2013.html),那么Java 6发现的新bug Oracle公司也就不再会去修改,这对用户来说就是不好的消息。 在前几天发布的Hadoop 2.7.0 (《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》)中的一个重要的 w397090770 10年前 (2015-05-06) 7512℃ 1评论4喜欢
和Hadoop类似,在Spark中也存在很多的Metrics配置相关的参数,它是基于Coda Hale Metrics Library的可配置Metrics系统,我们可以通过配置文件进行配置,通过Spark的Metrics系统,我们可以把Spark Metrics的信息报告到各种各样的Sink,比如HTTP、JMX以及CSV文件。Spark的Metrics系统目前支持以下的实例:master:Spark standalone模式的master进程;worker:S w397090770 10年前 (2015-05-05) 14434℃ 0评论15喜欢