Spark 1.2.0于美国时间2014年12月18日发布,Spark 1.2.0兼容Spark 1.0.0和1.1.0,也就是说不需要修改代码即可用,很多默认的配置在Spark 1.2发生了变化 1、spark.shuffle.blockTransferService由nio改成netty 2、spark.shuffle.manager由hash改成sort 3、在PySpark中,默认的batch size改成0了, 4、Spark SQL方面做的修改: spark.sql.parquet.c w397090770 10年前 (2014-12-19) 4608℃ 1评论2喜欢
2014 Spark亚太峰会12月6日在北京珠三角万豪酒店圆满收官,来自易观国际、Intel 、亚信科技、TalkingData、Spark亚太研究院、百度、京东、携程、IBM、星环科技、南京大学、洞庭国际智能硬件检测基地、 AdMaster、Docker中文社区、安徽象形科技的十八位演讲嘉宾为来自国内近305家企业,800多位一线开发者,带来了最干货的分享及一手的 w397090770 10年前 (2014-12-18) 29785℃ 251评论34喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第四次北京Spark meeting会议 w397090770 10年前 (2014-12-16) 10362℃ 73评论8喜欢
SchemaRDD在Spark SQL中已经被我们使用到,这篇文章简单地介绍一下如果将标准的RDD(org.apache.spark.rdd.RDD)转换成SchemaRDD,并进行SQL相关的操作。[code lang="scala"]scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6edd421fscala> case class Person(name: String, age:Int)defined class Perso w397090770 10年前 (2014-12-16) 21242℃ 0评论20喜欢
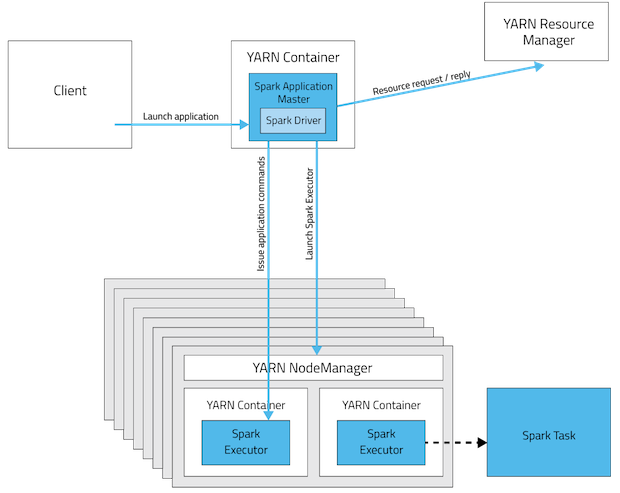
《Spark on YARN集群模式作业运行全过程分析》 《Spark on YARN客户端模式作业运行全过程分析》 《Spark:Yarn-cluster和Yarn-client区别与联系》 《Spark和Hadoop作业之间的区别》 《Spark Standalone模式作业运行全过程分析》(未发布) 我们都知道Spark支持在yarn上运行,但是Spark on yarn有分为两种模式yarn-cluster和yarn-cl w397090770 10年前 (2014-12-15) 58314℃ 4评论94喜欢
Akka学习笔记系列文章: 《Akka学习笔记:ACTORS介绍》 《Akka学习笔记:Actor消息传递(1)》 《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》 《Akka学习笔记:测试Actors》 《Akka学习笔记:Actor消息处理-请求和响应(1) 》 《Akka学习笔记:Actor消息处理-请求和响应(2) 》 《Akka学 w397090770 10年前 (2014-12-12) 10173℃ 1评论5喜欢
目前关于Spark方面的书籍已经有好几本了,这里列出了下面关于Spark 的书籍。部分书目前还没有发布,所以无法提供下载地址。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果你要找Hadoop相关书籍,可以看这里《精心收集的Hadoop学习资料(持续更新)》 1、大数据技术丛书:Spark快速 w397090770 10年前 (2014-12-08) 36133℃ 3评论58喜欢
这是Spark北京Meetup第四次活动,主要是SparkSQL专题。可以在这里报名,活动免费。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动时间 12月13日下午14:00活动地点 地址:淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 时间:13:20-13:40活动内容: w397090770 10年前 (2014-12-02) 5023℃ 0评论3喜欢
Spark 1.1.1于美国时间的2014年11月26日正式发布。基于branch-1.1分支,主要修复了一些bug。推荐所有的1.1.0用户更新到这个稳定版本。本次更新共有55位开发者参与。 spark.shuffle.manager仍然使用Hash作为默认值,说明了SORT的Shuffle还不怎么成熟。等待1.2版本吧。Fixes Spark 1.1.1修复了几个组件的bug。在下面将会列出一些代表性的b w397090770 10年前 (2014-11-28) 3343℃ 0评论5喜欢
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的。 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce T w397090770 10年前 (2014-11-11) 21155℃ 1评论34喜欢





![Spark学习书籍收集[持续更新]](https://www.iteblog.com/pic/iteblog.png)
