NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 784℃ 0评论2喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 5年前 (2020-05-14) 2328℃ 0评论4喜欢
我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数 w397090770 5年前 (2020-05-13) 1820℃ 0评论6喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2422℃ 0评论8喜欢
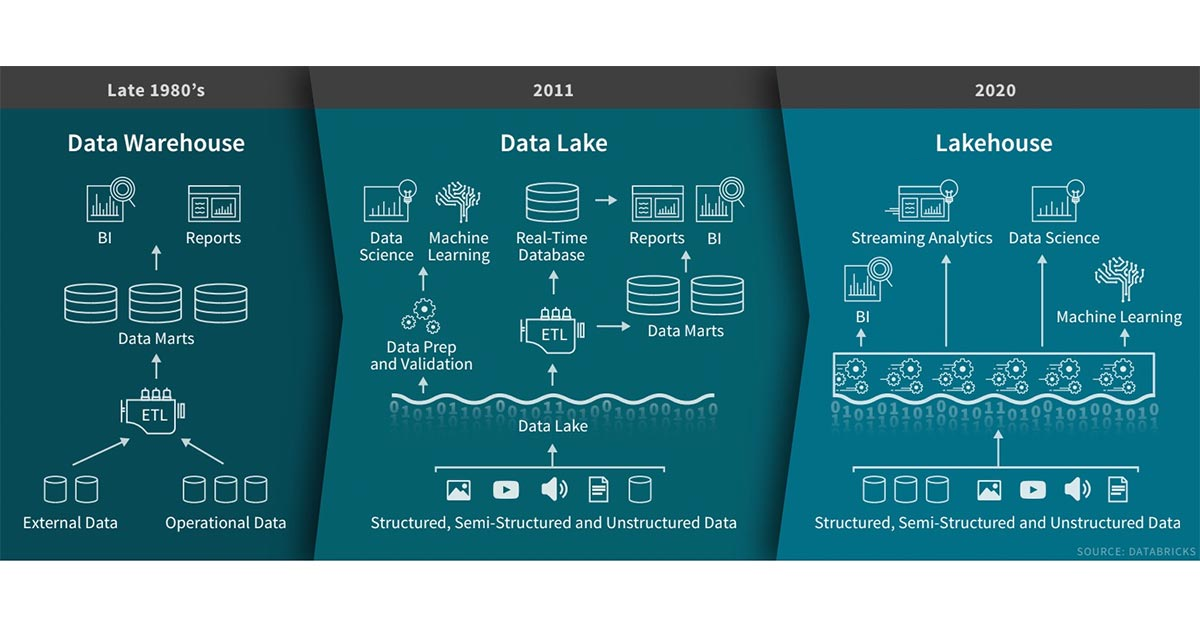
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3029℃ 0评论6喜欢
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 5年前 (2020-01-10) 1536℃ 0评论2喜欢
一、前言在 2019 年 1 月份的时候,我们发表过一篇博客 从 Hive 迁移到 Spark SQL 在有赞的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91% 以上,最后也分享一些在 Spark 踩过的坑和经验希望能帮助到大家 w397090770 5年前 (2020-01-05) 1749℃ 0评论2喜欢
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 5年前 (2019-12-19) 1826℃ 0评论10喜欢
Delta Lake 0.5.0 于2019年12月13日正式发布,正式版本可以到 这里 下载使用。这个版本支持多种查询引擎查询 Delta Lake 的数据,比如常见的 Hive、Presto 查询引擎。并发操作得到改进。当然,这个版本还是不支持直接使用 SQL 去增删改查 Delta Lake 的数据,这个可能得等到明年1月的 Apache Spark 3.0.0 的发布。好了,下面我们来详细介绍这个版本 w397090770 5年前 (2019-12-15) 1791℃ 0评论2喜欢
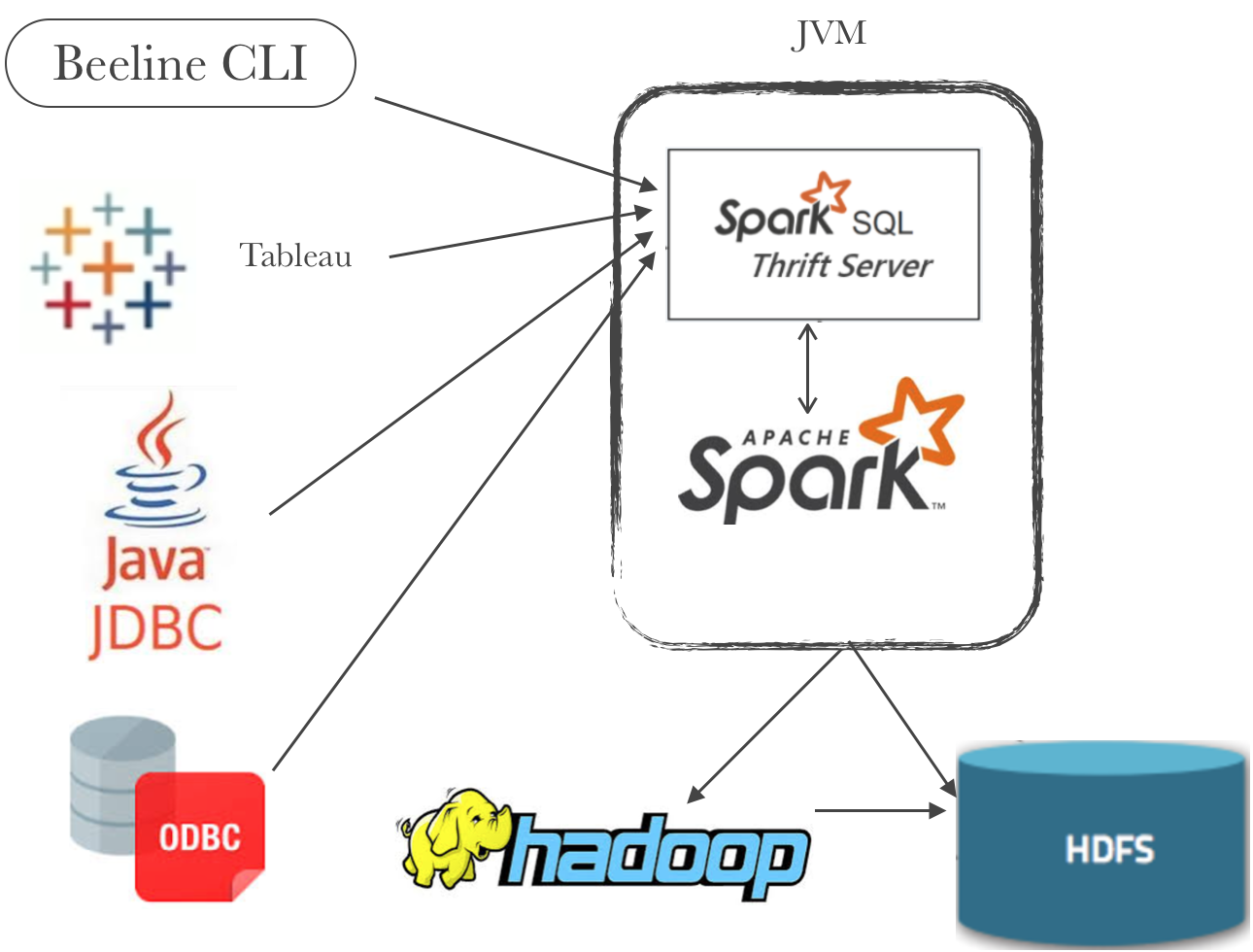
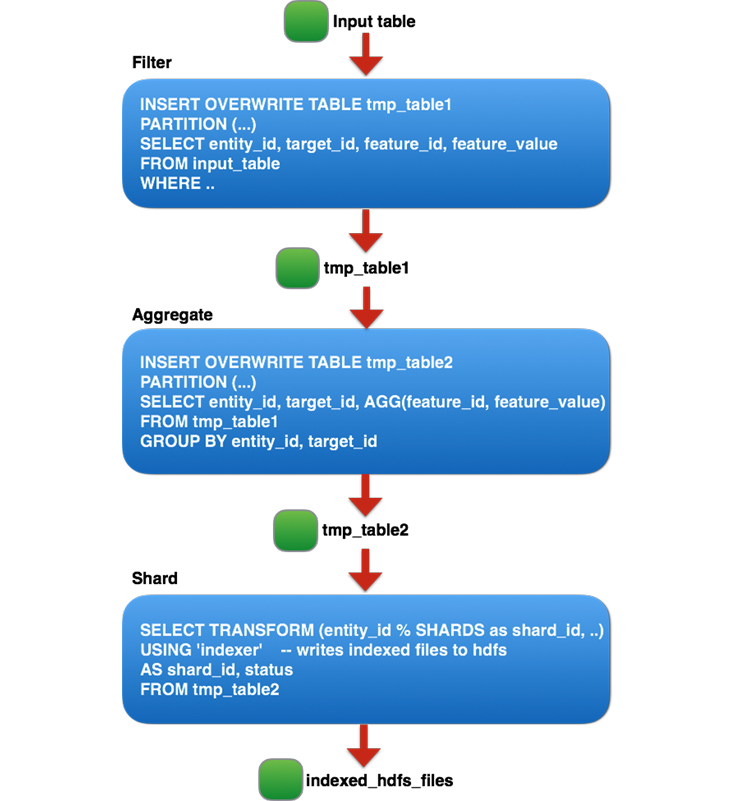
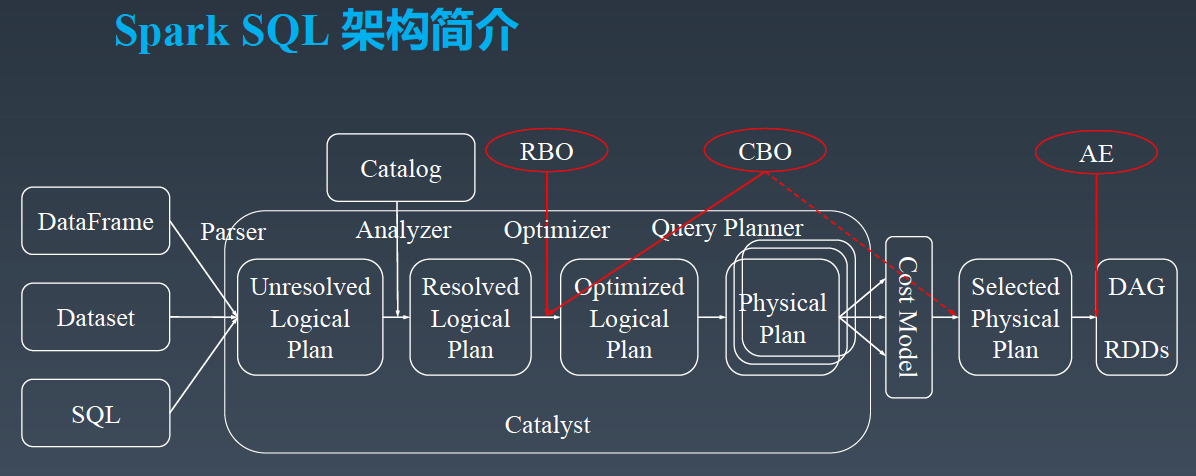
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 5年前 (2019-12-03) 4383℃ 0评论3喜欢