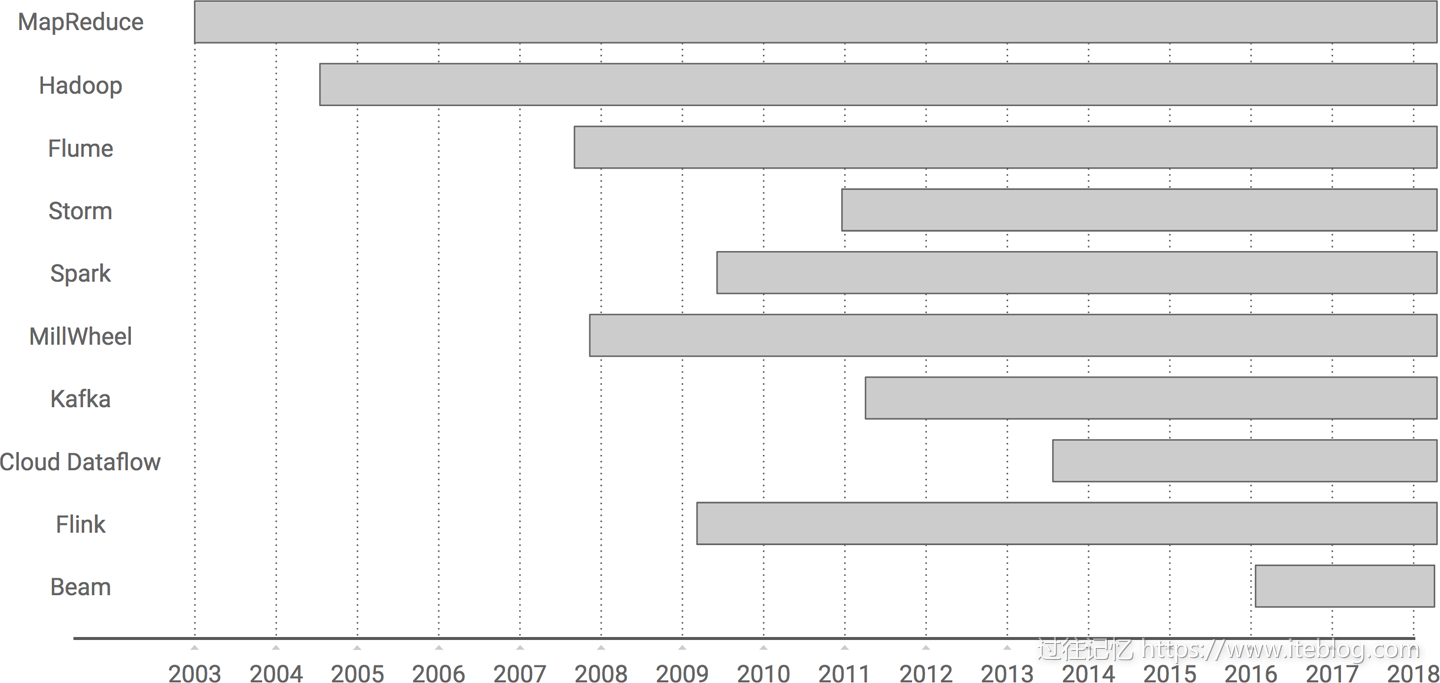
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10335℃ 2评论27喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16689℃ 1评论6喜欢