背景我们基于 Apache Hadoop® 的数据平台以最小的延迟支持了数百 PB 的分析数据,并将其存储在基于 HDFS 之上的数据湖中。我们使用 Apache Hudi™ 作为我们表的维护格式,使用 Apache Parquet™ 作为底层文件格式。我们的数据平台利用 Apache Hive™、Apache Presto™ 和 Apache Spark™ 进行交互和长时间运行的查询,满足 Uber 不同团队的各种需求。 w397090770 3年前 (2022-03-13) 2576℃ 0评论1喜欢
本资料来自2022年03月03日举办的 Alluxio Day 活动。分享议题 《Speed Up Uber’s Presto with Alluxio》,分享者 Liang Chen 和王北南。Uber 的 Liang Chen 和 Alluxio 的王北南将为大家呈现 Alluxio Local Cache 上线过程中遇到的实际问题和有趣的发现。他们的演讲涵盖了 Uber 的 Presto 团队如何解决 Alluxio 的本地缓存失效的问题。Liang Chen 还将分享他使用定 w397090770 3年前 (2022-03-07) 367℃ 0评论2喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Enabling Presto Caching at Uber with Alluxio》的分享,作者来自 Uber 的 Zhongting Hu 和 Alluxio 发 Dr. Beinan Wang。Zhongting Hu is Tech Lead Manager of the Interactive Analytics Team at Uber. He is leading and managing Presto ecosystems inside Uber.Dr. Beinan Wang is a software engineer from Alluxio and is the committer of PrestoDB. Prior to Alluxio, he w397090770 3年前 (2021-10-27) 254℃ 0评论0喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 469℃ 0评论3喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-09-05) 458℃ 0评论2喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据过往记忆大数据备注:以下的我们均代表 Uber 的 Hadoop 运维团队。介绍随着 Uber 业务的增长,Uber 公司在 5 年内将 Apache Hadoop(本文简称为“Hadoop”)部署扩展到 21000 台以上的节点,以支持各种分析和机器学习用例。我们组建了一支拥有各 w397090770 3年前 (2021-08-22) 771℃ 0评论4喜欢
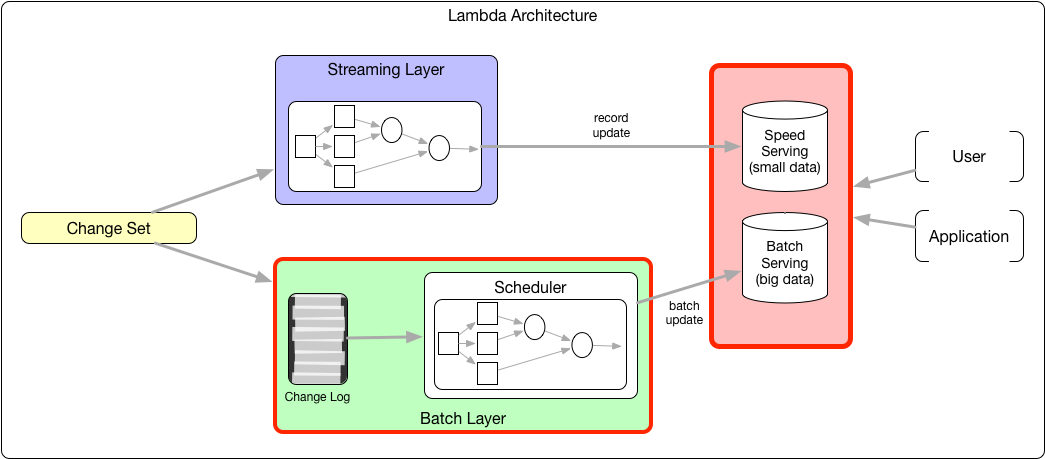
随着 Apache Parquet 和 Apache ORC 等存储格式以及 Presto 和 Apache Impala 等查询引擎的发展,Hadoop 生态系统有可能成为一个面向几分钟延迟工作负载的通用统一服务层。但是,为了实现这一点,需要在 Hadoop 分布式文件系统(HDFS)中实现高效、低延迟的数据摄取和数据准备。为了解决这个问题,Uber 构建了Hudi(被称为“hoodie”),这是一个 w397090770 5年前 (2019-11-21) 5200℃ 2评论9喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3281℃ 0评论8喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 946℃ 0评论1喜欢