MapReduce作业可以细分为map task和reduce task,而MRAppMaster又将map task和reduce task分为四种状态: 1、pending:刚启动但尚未向resourcemanager发送资源请求; 2、scheduled:已经向resourceManager发送资源请求,但尚未分配到资源; 3、assigned:已经分配到了资源且正在运行; 4、completed:已经运行完成。 map task的 w397090770 9年前 (2016-08-01) 3481℃ 0评论4喜欢
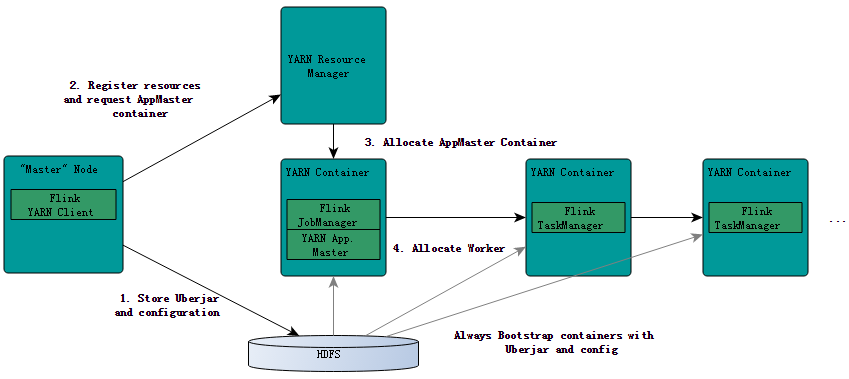
在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。 YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配置: 1、判断YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH等环境 w397090770 9年前 (2016-04-04) 6034℃ 0评论8喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 9年前 (2016-01-22) 12111℃ 16评论12喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 10年前 (2014-11-04) 19589℃ 5评论12喜欢