本文仅仅是简单地介绍如何在Ubuntu/Debian系统上安装Node.js(任何版本)和npm(Node Package Manager的简写),其他类Linux系统安装步骤和这个类似。 一、更新你的系统[code lang="bash"]iteblog# sudo apt-get updateiteblog# sudo apt-get install git-core curl build-essential openssl libssl-dev[/code] 二、安装Node.js 首先我们先从github上将Node w397090770 10年前 (2015-04-11) 27777℃ 0评论22喜欢
Marius Eriksen, Twitter Inc. marius@twitter.com (@marius) [translated by hongjiang(@hongjiang), tongqing(@tongqing)]序言 Scala是Twitter使用的主要应用编程语言之一。很多我们的基础架构都是用scala写的,我们也有一些大的库支持我们使用。虽然非常有效, Scala也是一门大的语言,经验教会我们在实践中要非常小心。 它有什么陷阱?哪些特 w397090770 10年前 (2015-04-11) 7442℃ 0评论3喜欢
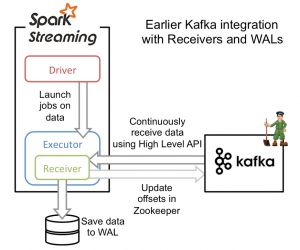
Apache Kafka近年来迅速地成为开源社区流行的流输入平台。同时我们也看到了Spark Streaming的使用趋势和它类似。因此,在Spark 1.3中,社区对Kafka和Spark Streaming的整合做了很多重要的提升。主要修改如下: 1、为Kafka新增了新的Direct API。这个API可以使得每个Kafka记录仅且被处理一次(processed exactly once),即使读取过程中出现了失 w397090770 10年前 (2015-04-10) 16798℃ 0评论24喜欢
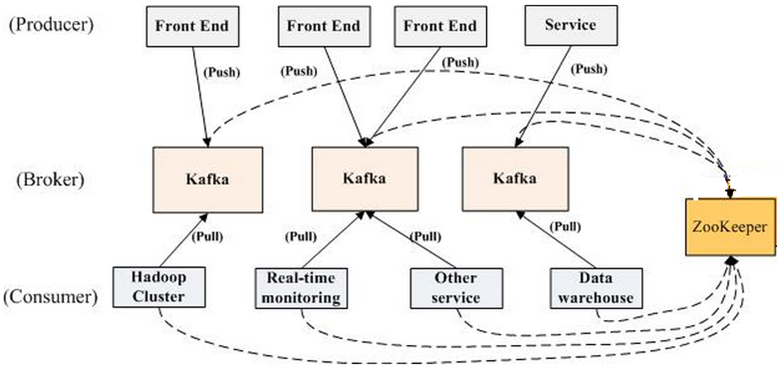
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源 w397090770 10年前 (2015-04-08) 7954℃ 2评论16喜欢
Spark Streaming是近实时(near real time)的小批处理系统。对给定的时间间隔(interval),Spark Streaming生成新的batch并对它进行一些处理。每个batch中的数据都代表一个RDD,但是如果一些batch中没有数据会发生什么事情呢?Spark Streaming将会产生EmptyRDD的RDD,它的定义如下:[code lang="scala"]package org.apache.spark.rddimport scala.reflect.ClassTagimport w397090770 10年前 (2015-04-08) 10149℃ 1评论11喜欢
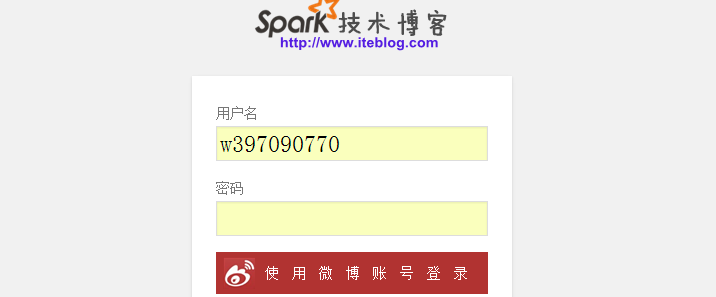
经过一晚上的奋战终于通过调用新浪登录的登录API替代Wordpress内置的登录注册模块。只要你有新浪微博帐号即可绑定到本博客。添加微博登录功能主要解决两个问题:(1)、方便用户登录/注册;(2)、防止机器人注册本网站。以下是登录页面图: 点击上面使用微博帐号登录即可调用微博登录。如果你是第一次登录,需 w397090770 10年前 (2015-04-04) 4997℃ 0评论3喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19164℃ 3评论15喜欢
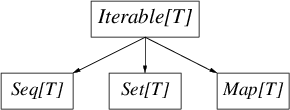
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 在本博客的《Spark RDD API扩展开发(1)》文章中我介绍了如何在现有的RDD中添加自定义的函数。本文将介绍如何自定义一个RDD类,假如我们想对没见商品进行打折,我们想用Action操作来实现这个操作,下面我将定义IteblogDiscountRDD类来计算商品的打折,步骤如 w397090770 10年前 (2015-03-31) 12036℃ 0评论8喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 我们都知道,Apache Spark内置了很多操作数据的API。但是很多时候,当我们在现实中开发应用程序的时候,我们需要解决现实中遇到的问题,而这些问题可能在Spark中没有相应的API提供,这时候,我们就需要通过扩展Spark API来实现我们自己的方法。我们可 w397090770 10年前 (2015-03-30) 7228℃ 2评论15喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-30) 4847℃ 0评论4喜欢