如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 11年前 (2014-09-10) 38767℃ 7评论32喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 11年前 (2014-09-08) 18441℃ 177评论16喜欢
本文详细地介绍了如何将Hadoop上的Mapreduce程序转换成Spark的应用程序。有兴趣的可以参考一下:The key to getting the most out of Spark is to understand the differences between its RDD API and the original Mapper and Reducer API.Venerable MapReduce has been Apache Hadoop‘s work-horse computation paradigm since its inception. It is ideal for the kinds of work for which Hadoop was originally des w397090770 11年前 (2014-09-07) 6451℃ 1评论9喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 11年前 (2014-09-04) 25740℃ 21评论40喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 8月31日(13:30-17:30),杭州第 w397090770 11年前 (2014-09-01) 26679℃ 230评论17喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 下面是Spark meetup(Beijing)第 w397090770 11年前 (2014-08-29) 24111℃ 204评论16喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Font Awesome是一种web font,它包含了几乎所有常用的图标,比如Twitter、facebook等等。用户可以自定义这些图标字体,包括大小、颜色、阴影效果以及其它可以通过CSS控制的属性。它有以下的优点: 1、像矢量图形一样,可以无限放大 2、只 w397090770 11年前 (2014-08-20) 44374℃ 1评论115喜欢
备份数据库,还原数据库的情况,我们一般用一下两种方式来处理:1.使用into outfile 和 load data infile导入导出备份数据这种方法的好处是,导出的数据可以自己规定格式,并且导出的是纯数据,不存在建表信息,你可以直接导入另外一个同数据库的不同表中,相对于mysqldump比较灵活机动。我们来看下面的例子:(1)下面 w397090770 11年前 (2014-08-15) 4822℃ 0评论5喜欢
Spark SQL也公布了很久,今天写了个程序来看下Spark SQL、Spark Hive以及直接用Hive执行的效率进行了对比。以上测试都是跑在YARN上。 首先我们来看看我的环境: 3台DataNode,2台NameNode,每台机器20G内存,24核 数据都是lzo格式的,共336个文件,338.6 G 无其他任务执行如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 w397090770 11年前 (2014-08-13) 50077℃ 9评论51喜欢
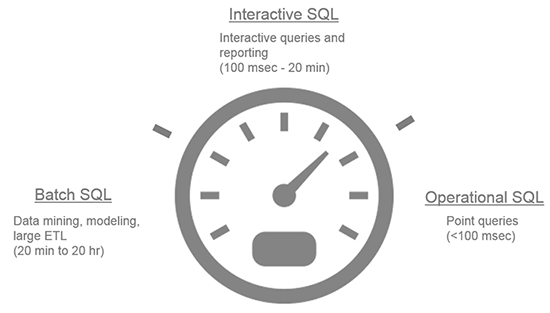
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 11年前 (2014-08-11) 9923℃ 0评论14喜欢