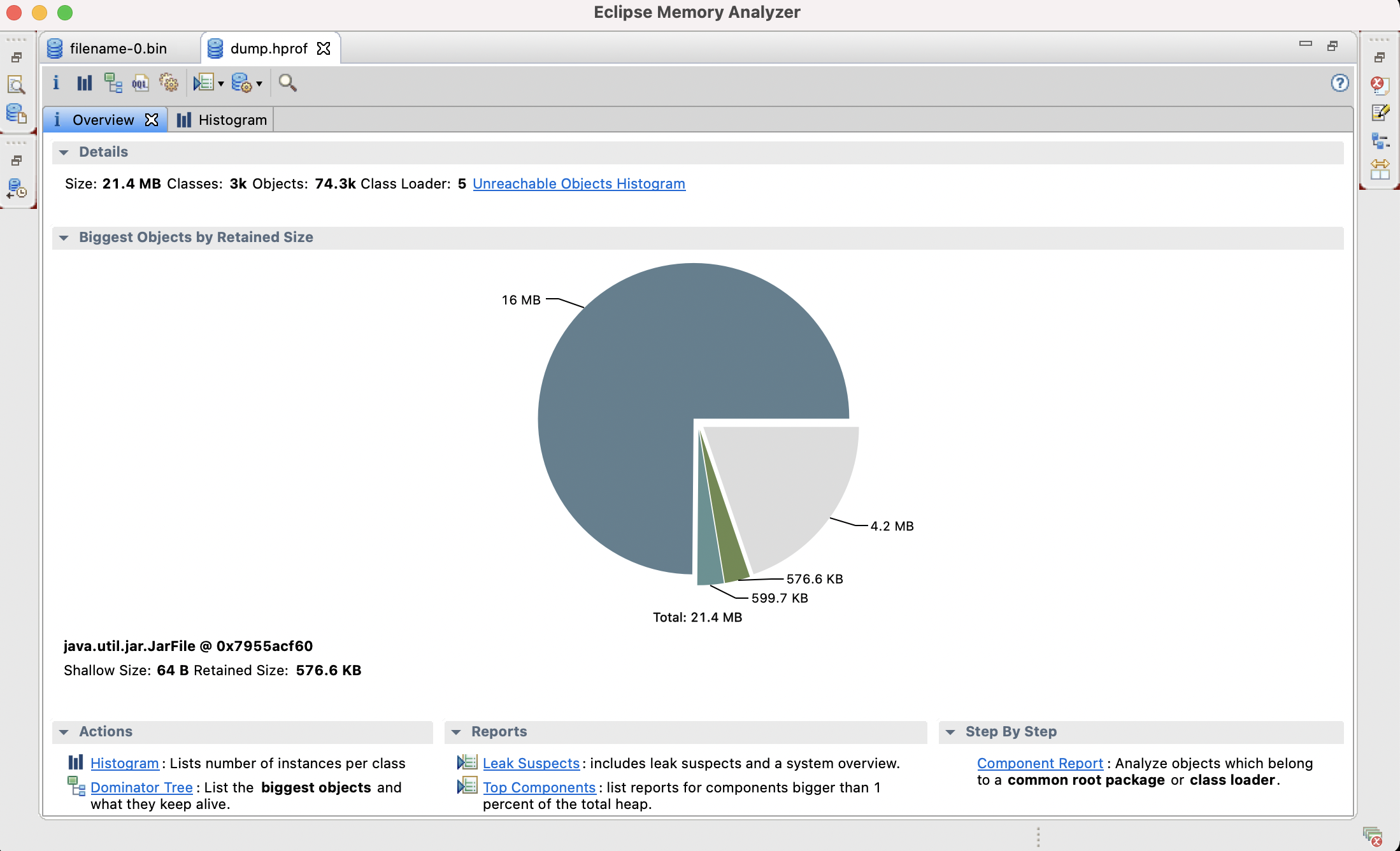
在安装完 JDK 之后,会自带安装一些常用的小工具,而 jmap 就是其中一个比较常用的。jmap 打印给定进程、core file 或远程调试服务器的共享对象内存映射或堆内存细节。我们可以查看下 jmap 的命令使用:[code lang="bash"]iteblog@iteblog.com:~|⇒ jmapUsage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <co w397090770 4年前 (2021-08-02) 869℃ 0评论0喜欢
在实际开发过程中,我们可能会每开发一些代码就会把这些代码进行提交,以防止一些意外;但是随着提交的 commits 数越来越多,一方面维护起来不便,另一方面可能会造成版本控制的混乱,为了解决这个问题,我们可以把多个 commit 合并成一个。比如下面这个 MR 一共提交了两次:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 4年前 (2021-07-31) 1181℃ 0评论3喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 4年前 (2021-07-31) 527℃ 0评论4喜欢
背景 现状 HDFS 全称是 Hadoop Distributed File System,其本身是 Apache Hadoop 项目的一个模块,作为大数据存储的基石提供高吞吐的海量数据存储能力。自从 2006 年 4 月份发布以来,HDFS 目前依然有着非常广泛的应用,以字节跳动为例,随着公司业务的高速发展,目前 HDFS 服务的规模已经到达“双 10”的级别: 单集群节点 10 万台级别单 w397090770 4年前 (2021-07-29) 569℃ 0评论2喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 w397090770 4年前 (2021-07-17) 328℃ 0评论1喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 w397090770 4年前 (2021-07-09) 612℃ 0评论1喜欢
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 w397090770 4年前 (2021-07-02) 1368℃ 0评论4喜欢
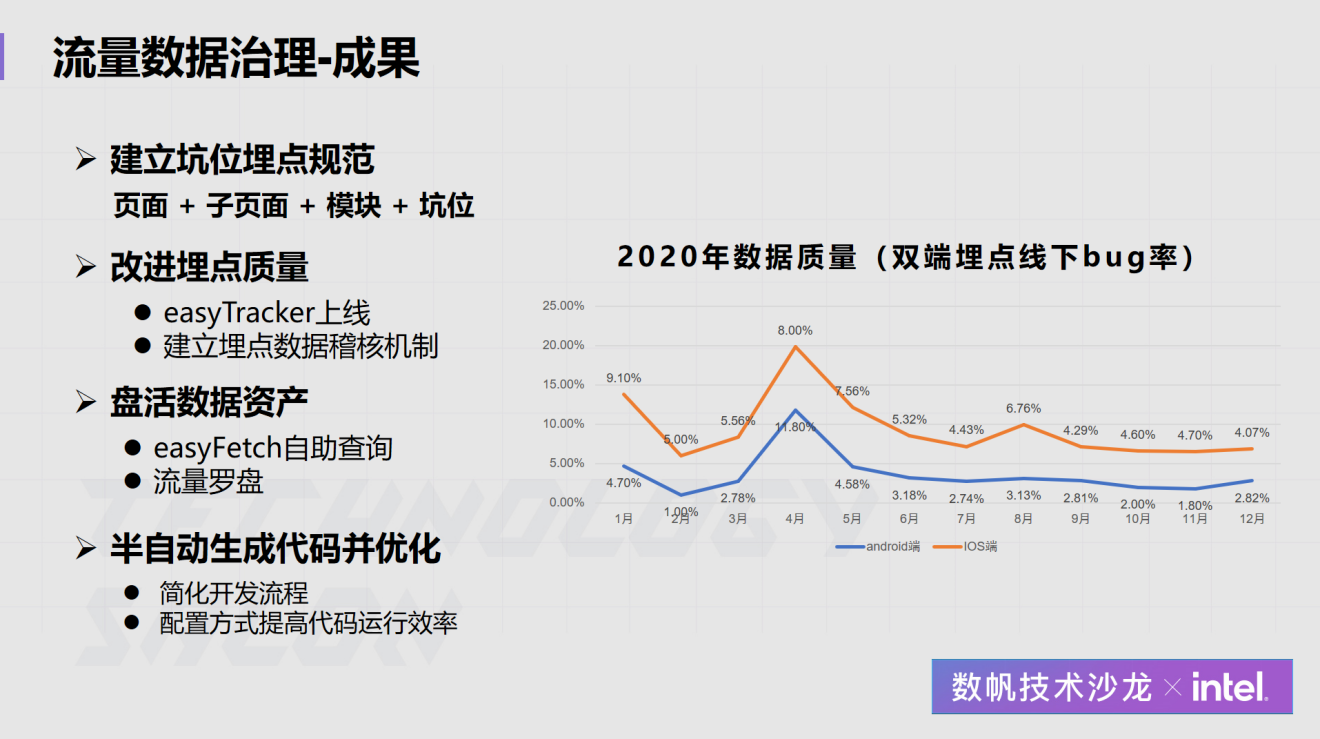
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 4年前 (2021-06-30) 1008℃ 0评论1喜欢
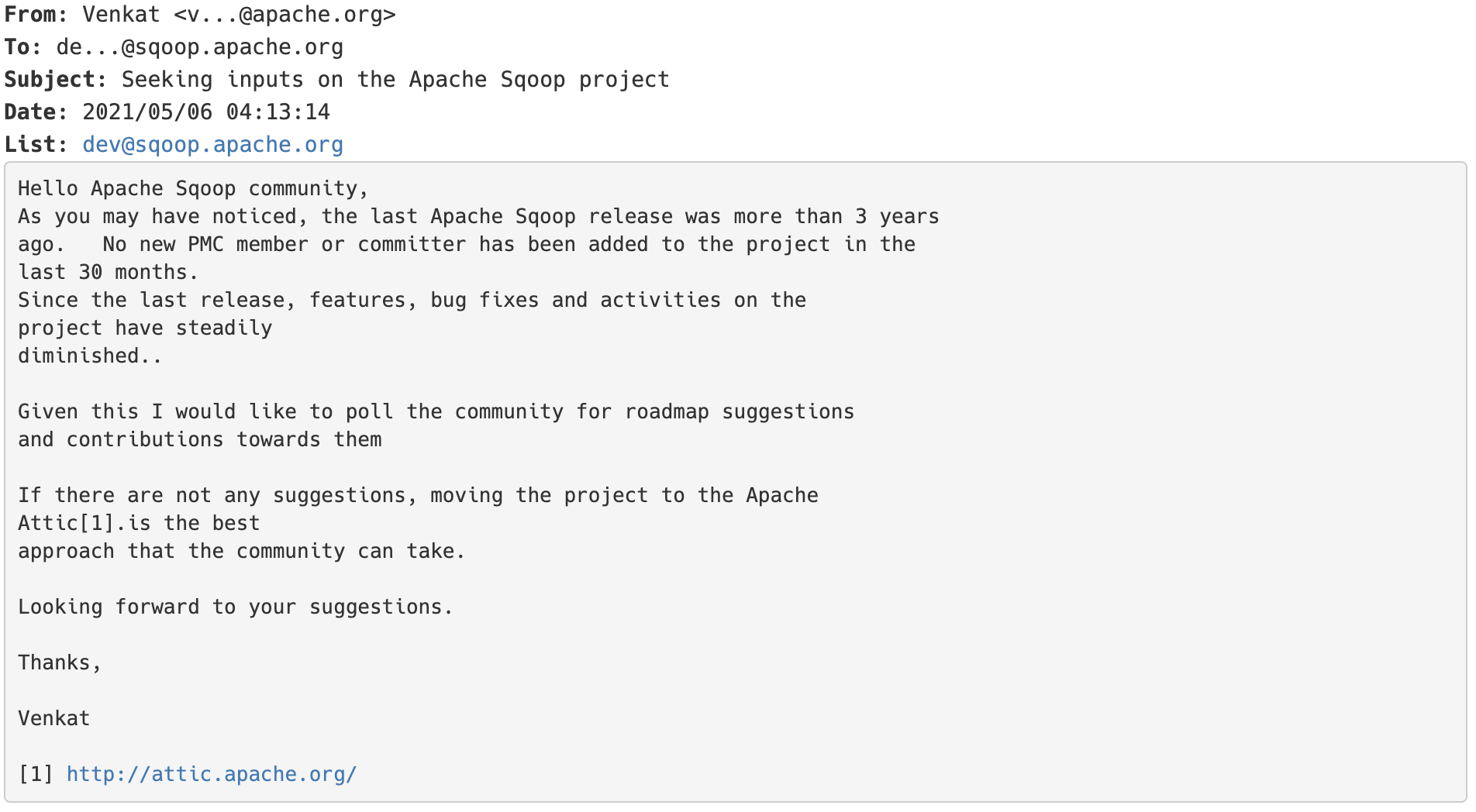
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 4年前 (2021-06-27) 772℃ 0评论2喜欢
和 MySQL 以及其他计算引擎类似,MongoDB 给我们提供了 explain 命令来查看某个查询的执行计划,其使用也比较简单,具体如下:[code lang="bash"]db.collection.explain().<method(...)>[/code]explain 命令默认是打印出查询的 queryPlanner,也就是什么参数都不传递。从 3.5.5 版本开始,explain 命名还支持 executionStats 和 allPlansExecution 两种运行模式 w397090770 4年前 (2021-06-21) 433℃ 0评论0喜欢