背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2405℃ 0评论8喜欢
Java 14 计划将会在今年的3月17日发布,Java 14 包含的 JEP(Java Enhancement Proposals 的缩写,Java 增强建议)比 Java 12 和 13 两个版本加起来还要多。那么,对于每天编写和维护代码的 Java 开发人员来说,哪个特性值得我们关注呢?如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文我将介绍以下几个重 w397090770 5年前 (2020-03-07) 945℃ 0评论2喜欢
目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 w397090770 5年前 (2020-03-05) 4005℃ 0评论2喜欢
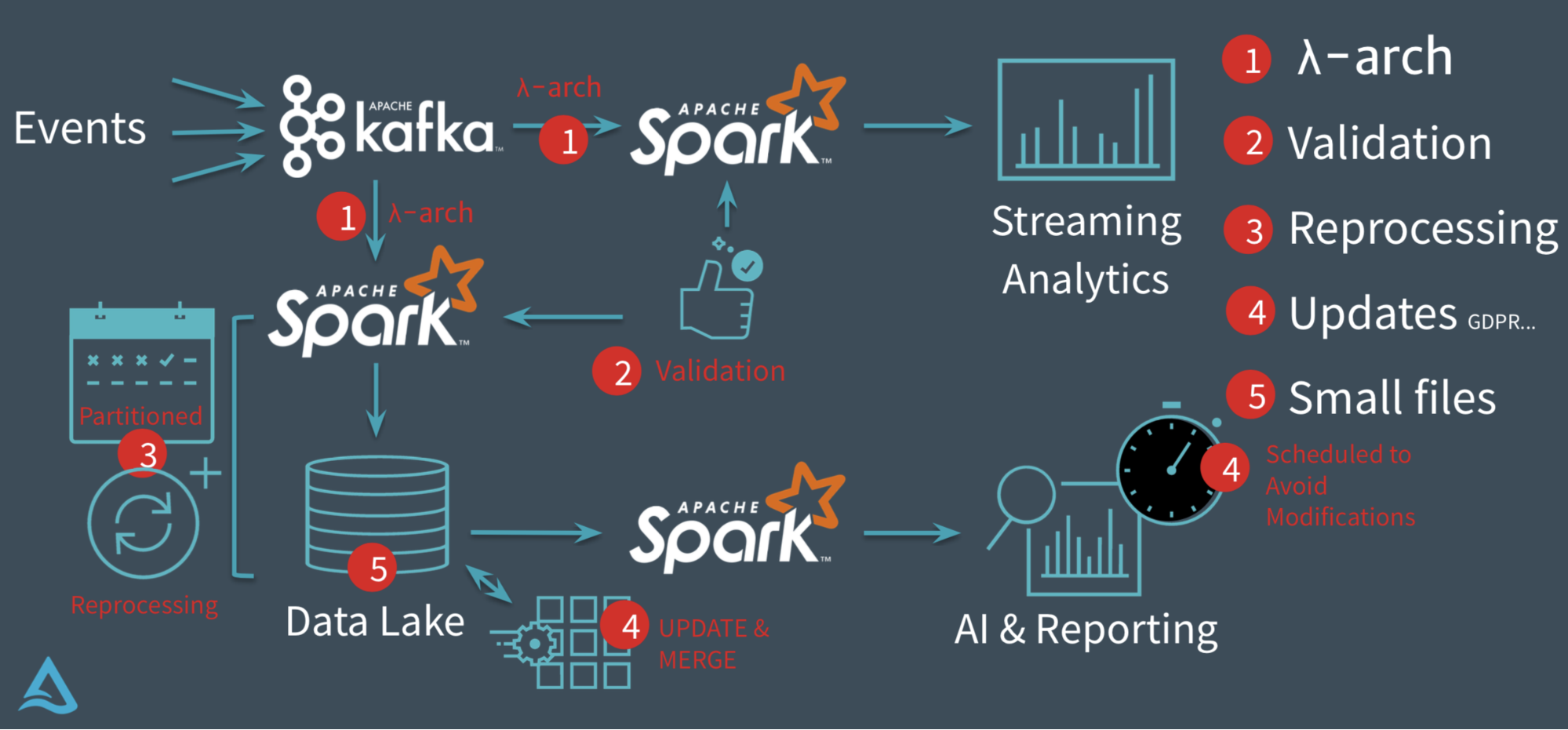
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主题覆盖度、性能、易用性、可扩展性及数 w397090770 5年前 (2020-03-01) 2024℃ 0评论7喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase w397090770 5年前 (2020-02-23) 3013℃ 0评论6喜欢
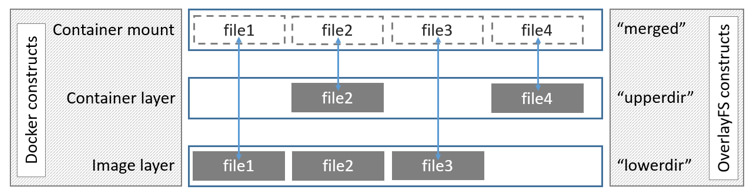
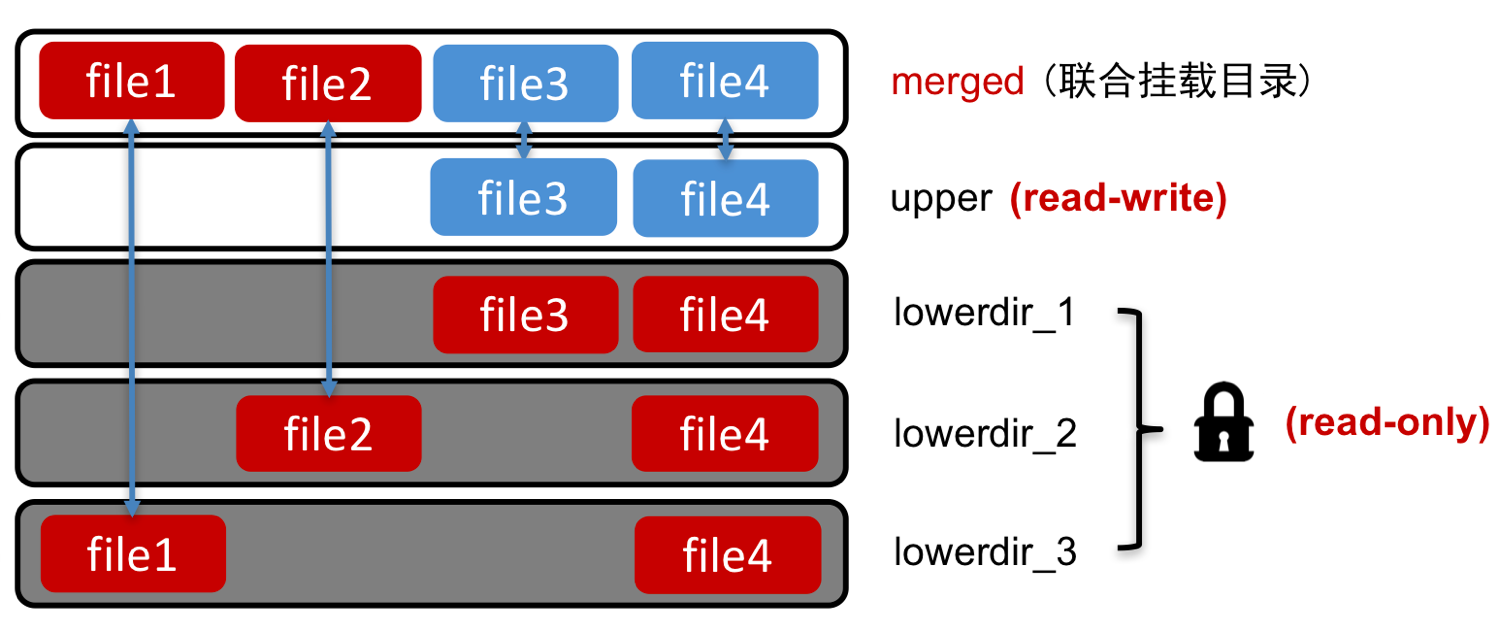
我们在 Docker 入门教程:镜像分层 和 Docker 入门教程:Docker 基础技术 Union File System 已经介绍了一些前提基础知识,本文我们来介绍 Union File System 在 Docker 的应用。为了使 Docker 能够在 container 的 writable layer 写一些比较小的数据(如果需要写大量的数据可以通过挂载盘去写),Docker 为我们实现了存储驱动(storage drivers)。Docker 使 w397090770 5年前 (2020-02-16) 799℃ 0评论5喜欢
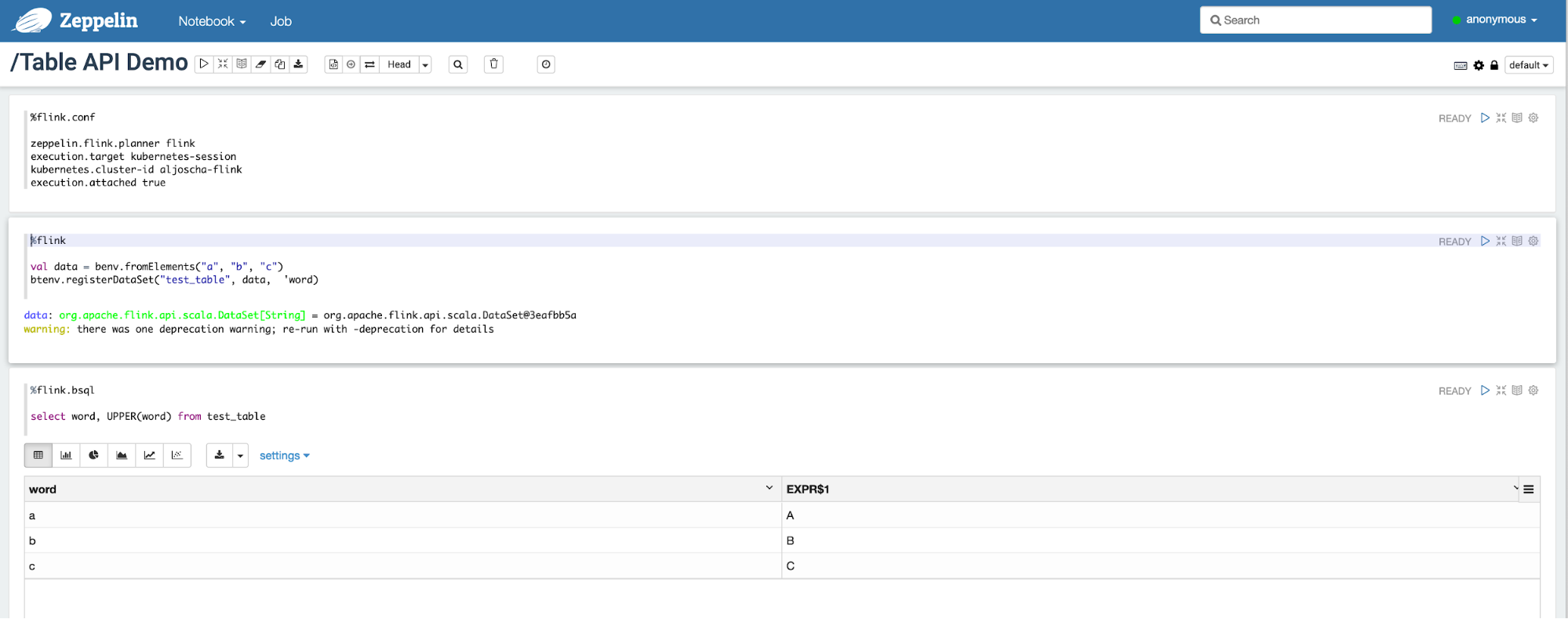
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3477℃ 0评论3喜欢
我们在前面 《Docker 入门教程:镜像分层》 文章中介绍了 Docker 为什么构建速度非常快,其原因就是采用了镜像分层,镜像分层底层采用的技术就是本文要介绍的 Union File System。Linux 支持多种 Union File System,比如 aufs、OverlayFS、ZFS 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众帐号:iteblog_hadoopaufs & OverlayF w397090770 5年前 (2020-02-09) 1293℃ 0评论4喜欢
我们在前面的 《Docker 入门教程:快速开始 》文章了解到镜像和容器的概念。本文将了解一下 Docker 的镜像分层(Layer)的概念,在 Docker 的官方文档对 Layer 的定义如下(参见这里):In an image, a layer is modification to the image, represented by an instruction in the Dockerfile. Layers are applied in sequence to the base image to create the final image. When an image is up w397090770 5年前 (2020-02-05) 1986℃ 0评论6喜欢
本文来自 2019年9月23日至26日在纽约举办的 Strata Data Conference,分享者是来自 Cloudera 的 Wangda Tan 和 Wei-Chiu Chuang,会议页面 https://conferences.oreilly.com/strata/strata-ny-2019/public/schedule/detail/77506。请关注 过往记忆大数据 微信公众号,并在后台回复 hadoop_3 关键字获取本文的 PPT 下载地址。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 5年前 (2020-02-04) 2421℃ 2评论5喜欢