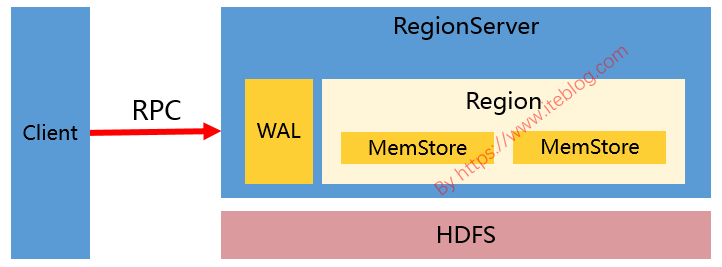
我们知道,一张 HBase 表包含一个或多个列族。HBase 的官方文档中关于 HBase 表的列族的个数有两处描述:A typical schema has between 1 and 3 column families per table. HBase tables should not be designed to mimic RDBMS tables. 以及 HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low. 上面两句话其实都是 w397090770 6年前 (2019-01-01) 4493℃ 1评论13喜欢
本文来自本人于2018年12月25日在 HBase生态+Spark社区钉钉大群直播,本群每周二下午18点-19点之间进行 HBase+Spark技术分享。加群地址:https://dwz.cn/Fvqv066s。本文 PPT 下载:关注 iteblog_hadoop 微信公众号,并回复 HBase_Rowkey 关键字获取。为什么Rowkey这么重要RowKey 到底是什么如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 6年前 (2018-12-25) 7510℃ 0评论29喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,dataArtisans(Apache Flink 商业母公司),华为、腾讯、滴滴、美团以及字节跳动等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大 w397090770 6年前 (2018-12-22) 4031℃ 0评论17喜欢
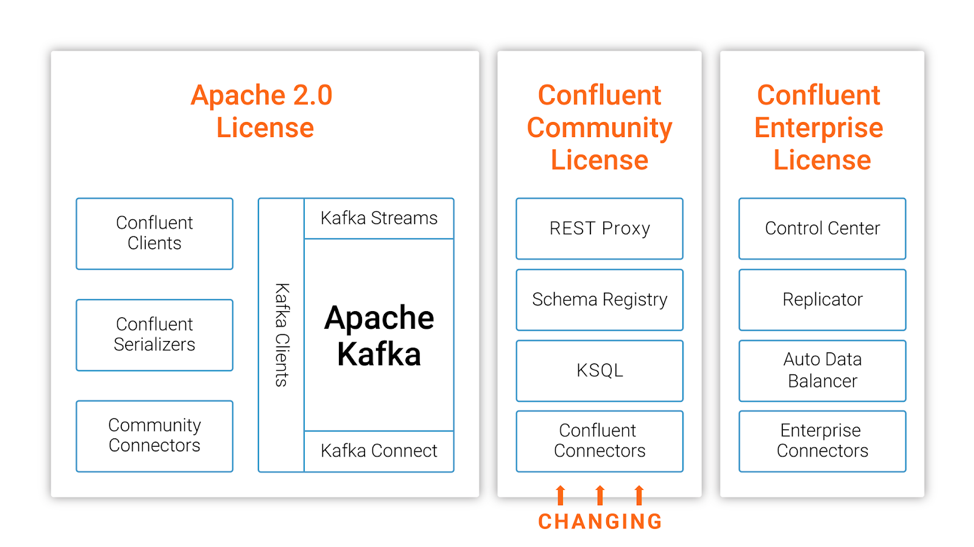
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 6年前 (2018-12-15) 2018℃ 0评论3喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方法来测试正确性。图像数据源通过给我们提供可以编码的标准表 w397090770 6年前 (2018-12-13) 2477℃ 0评论4喜欢
Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始,Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro Data Source for Apache Spark。除此之外,它还提供以下功能:新函数 from_avro() 和 to_avro() w397090770 6年前 (2018-12-11) 3182℃ 0评论9喜欢
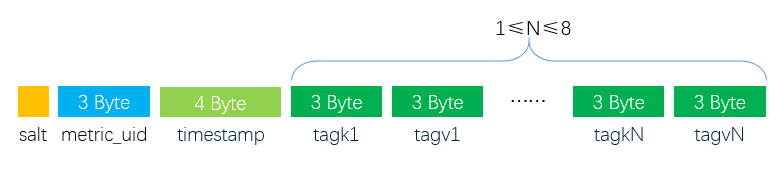
我们在 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章中已经简单介绍了 OpenTSDB 的 RowKey 设计的思路,并简单介绍了列簇以及列名的组成。本文将比较详细的介绍 OpenTSDB 在 HBase 的数据存储模型。OpenTSDB RowKey 设计关于 OpenTSDB 的 RowKey 为什么这么设计可以参见 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》文章了。这里主要介绍 R w397090770 6年前 (2018-12-05) 3008℃ 0评论3喜欢
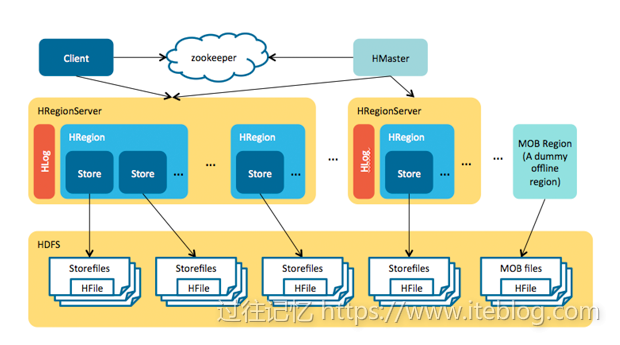
《Apache HBase中等对象存储MOB压缩分区策略介绍》 文章中介绍了 MOB 的一些压缩实现,并提及了一些 MOB 的一些简单使用,本文将详细地介绍 HBase MOB 的使用,本指南适合入门的开发者。将不同大小的文件(比如图片、文档等)存储到 HBase 非常的简单方便。从技术上来说,HBase 可以直接在一个单元格(Cell)存储大小到10MB的二进制对 w397090770 6年前 (2018-12-03) 2849℃ 0评论5喜欢
HDFS 快照是从 Hadoop 2.1.0-beta 版本开始引入的新功能,详见 HDFS-2802。概述HDFS 快照(HDFS Snapshots)是文件系统在某个时间点的只读副本。可以在文件系统的子树或整个文件系统上创建快照。快照的常见用途主要包括数据备份,防止用户误操作和容灾恢复。HDFS 快照的实现非常高效:快照的创建非常迅速:除去 inode 的查找时间, w397090770 6年前 (2018-12-02) 2173℃ 0评论3喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 6年前 (2018-11-29) 4310℃ 2评论16喜欢