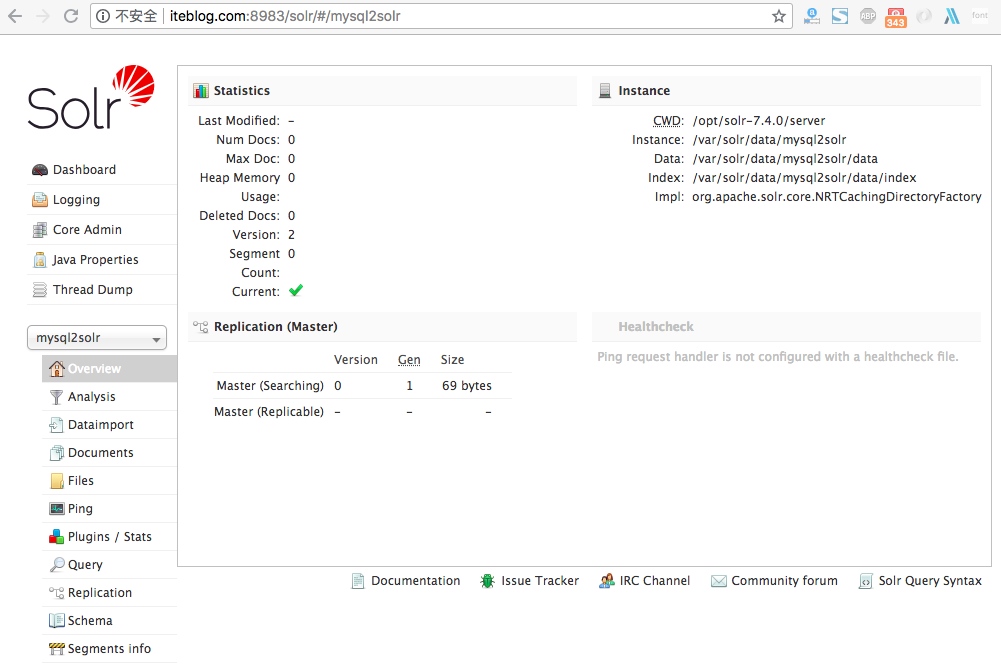
如果你正在按照 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章介绍的步骤来将 MySQL 里面的数据导入到 Solr 中,但是在创建 Core/Collection 的时候出现了以下的异常[code lang="bash"]2018-08-02 07:56:17.527 INFO (qtp817348612-15) [ x:mysql2solr] o.a.s.m.r.SolrJmxReporter Closing reporter [org.apache.solr.metrics.reporters.SolrJmxReporter@47d9861c: rootName = null, domain = solr.cor w397090770 7年前 (2018-08-07) 1075℃ 0评论2喜欢
关于分页方式导入全量数据请参照《将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中》。在前面几篇文章中我们介绍了如何通过 Solr 的 post 命令将各种各样的文件导入到已经创建好的 Core 或 Collection 中。但有时候我们需要的数据并不在文件里面,而是在别的系统中,比如 MySql 里面。不过高兴的是,Solr 针对这些数据也提供了 w397090770 7年前 (2018-08-06) 1989℃ 0评论2喜欢
到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th w397090770 7年前 (2018-08-01) 1736℃ 0评论4喜欢
Apache Kafka 2.0.0 在昨天正式发布了,其包含了许多重要的特性,这里我列举了一些比较重要的:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop增加了前缀通配符访问控制(ACL)的支持,详见 KIP-290,这样我们可以更加细粒度的进行访问控制;更全面的数据安全支持,KIP-255 里面添加了一个框架, w397090770 7年前 (2018-07-31) 3994℃ 0评论6喜欢
在 《Apache Solr 安装部署及索引创建》 文章里面我创建了一个名为 iteblog 的 core,并在里面导入了一些测试数据,然后在 《使用 Apache Solr 检索数据》 里面介绍了 Solr 中一些简单的查询。可能有同学按照上面文章介绍,在使用下面的查询发现啥都查不到:[code lang="bash"][root@iteblog.com /opt/solr-7.4.0]$ curl http://iteblog.com:8983/solr/iteblog/select w397090770 7年前 (2018-07-27) 1535℃ 0评论4喜欢
在 《Apache Solr 安装部署及索引创建》 文章中,我们搭建好一个单机版的 Solr 服务,并创建好一个名为 iteblog 的 core,iteblog 的索引数据是存放在 instanceDir 参数的 data 目录下。这会有以下几个问题:如果索引数据很大,可能本地的文件夹无法存储索引数据存放在本地,可能会导致索引数据丢失等幸运的是,Solr 支持将索引和事 w397090770 7年前 (2018-07-25) 1842℃ 0评论4喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* w397090770 7年前 (2018-07-24) 1498℃ 0评论4喜欢
Solr 介绍Apache Solr 是基于 Apache Lucene™ 构建的流行,快速,开源的企业搜索平台。Solr 具有高可靠性,可扩展性和容错性,可提供分布式索引,复制和负载均衡查询,自动故障转移和恢复以及集中配置等特性。 Solr 为世界上许多大型互联网站点提供搜索和导航功能。Solr 是用 Java 编写、运行在 Servlet 容器(如 Apache Tomcat 或Jetty) w397090770 7年前 (2018-07-24) 2867℃ 0评论3喜欢
Hadoop的一大基本原则是移动计算的开销要比移动数据的开销小。因此,Hadoop通常是尽量移动计算到拥有数据的节点上。这就使得Hadoop中读取数据的客户端DFSClient和提供数据的Datanode经常是在一个节点上,也就造成了很多“Local Reads”。最初设计的时候,这种Local Reads和Remote Reads(DFSClient和Datanode不在同一个节点)的处理方式都是一 w397090770 7年前 (2018-07-22) 123℃ 0评论0喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 7年前 (2018-07-22) 9733℃ 0评论10喜欢