Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 7年前 (2018-05-09) 10817℃ 0评论22喜欢
一致性问题在介绍分布式系统一致性问题之前,我们先来了解一下副本概念。分布式系统会存在许多异常问题,比如机器宕机;为了提供高可用服务,一般会将数据或者服务部署到很多机器上,这些机器中的数据或服务可以称为副本。如果其中任何一台节点出现故障,用户可以访问其他机器上的数据或服务。由于副本的存在,如 w397090770 7年前 (2018-05-04) 4660℃ 0评论10喜欢
二叉树的前序遍历给你二叉树的根节点 root ,返回它节点值的 前序 遍历。示例 1:输入: [code lang="bash"] 1 \ 2 / 3 [/code]输出: [1,2,3]示例 2:输入: [code lang="bash"] 1 /2[/code]输出: [1,2]递归首先我们需要了解什么是二叉树的前序遍历:按照访问根节点——左子树——右子树的方式遍历这棵树,而在 w397090770 7年前 (2018-05-02) 68℃ 0评论0喜欢
本文来自 恩爸 的文章,原文地址:https://blog.csdn.net/zzcclp/article/details/80161130前言一个偶然的机会,从某Spark微信群知道了CarbonData,从断断续续地去了解,到测试 1.2 版本,再到实际应用 1.3 版本的流式入库,也一年有余,在这期间,得到了 CarbonData 社区的陈亮,李昆,蔡强等大牛的鼎力支持,自己也从认识CarbonData 到应用 Carbo w397090770 7年前 (2018-05-02) 2777℃ 0评论7喜欢
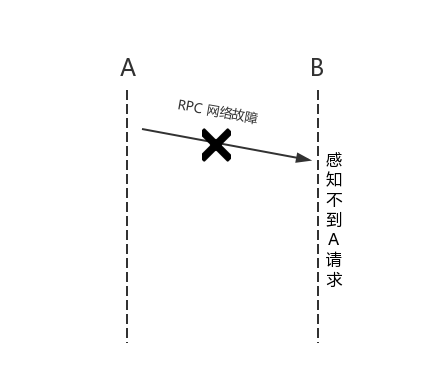
在传统的单机系统中,我们调用一个函数,这个函数要么返回成功,要么返回失败,其结果是确定的。可以概括为传统的单机系统调用只存在两态(2-state system):成功和失败。然而在分布式系统中,由于系统是分布在不同的机器上,系统之间的请求就相对于单机模式来说复杂度较高了。具体的,节点 A 上的系统通过 RPC (Remote Proc w397090770 7年前 (2018-04-20) 2555℃ 0评论9喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 7年前 (2018-04-08) 3569℃ 0评论15喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19895℃ 4评论93喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 7年前 (2018-03-28) 5365℃ 3评论24喜欢
我们知道,Zookeeper 会将所有事务操作的数据记录到日志文件中,这个文件的存储路径可以通过 dataLogDir 参数配置。在写数据之前,Zookeeper 会采用磁盘空间预分配策略;磁盘空间预分配策略主要有以下几点好处:可以让文件尽可能的占用连续的磁盘扇区,减少后续写入和读取文件时的磁盘寻道开销;迅速占用磁盘空间,防止使用 w397090770 7年前 (2018-03-23) 2097℃ 0评论5喜欢
原文名:Paxos Made Simple [PDF下载] Leslie Lamport 2001/11/01翻译:phylipsbmy 原译文链接: http://duanple.blog.163.com/blog/static/709717672011440267333/审校:Jerry Lee oldratlee<at>gmail<dot>com译序“在PODC2001会议上,我总是听到人们在抱怨Paxos算法是那么的难以理解。人们总是被那些古希腊的名称弄得晕头转向,而使得他们觉得论文难以理解 w397090770 7年前 (2018-03-12) 3680℃ 0评论9喜欢