我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 7年前 (2018-01-14) 10200℃ 2评论23喜欢
本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 7年前 (2018-01-11) 91098℃ 0评论78喜欢
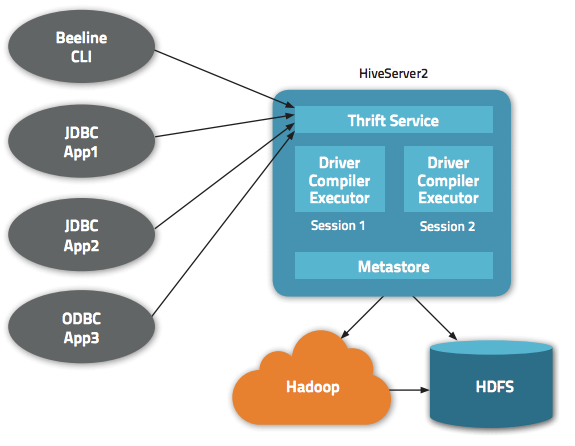
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 7年前 (2018-01-11) 13467℃ 5评论18喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 7年前 (2018-01-09) 16267℃ 1评论43喜欢
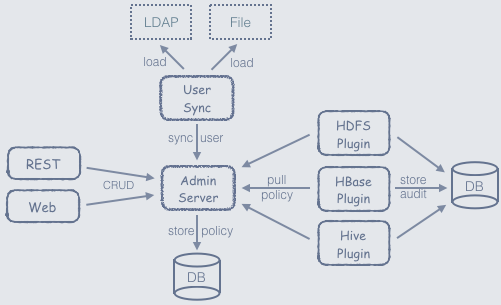
Apache Ranger 是一个用在 Hadoop 平台上并提供操作、监控、管理综合数据安全的框架。Ranger 的愿景是在 Apache Hadoop 生态系统中提供全面的安全性。 目前,Apache Ranger 支持以下 Apache 项目的细粒度授权和审计:Apache HadoopApache HiveApache HBaseApache StormApache KnoxApache SolrApache KafkaYARN对于上面那些受支持的 Hadoop 组件,Ranger 通过访 w397090770 7年前 (2018-01-07) 9397℃ 2评论16喜欢
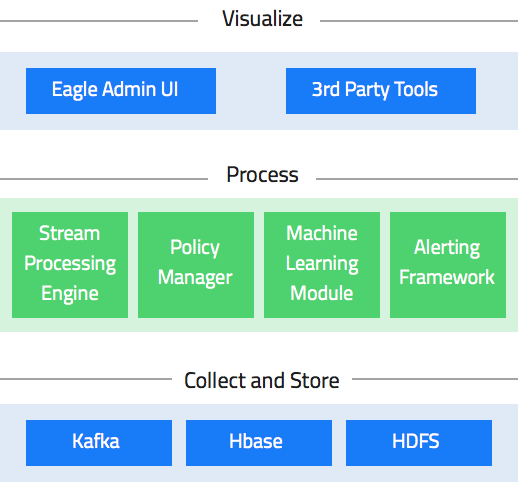
Apache Eagle 是由 eBay 公司开源的一个识别大数据平台上的安全和性能问题的开源解决方案。该项目于2017年1月10日正式成为 Apache 顶级项目。 Apache Eagle 提供一套高效分布式的流式策略引擎,具有高实时、可伸缩、易扩展、交互友好等特点,同时集成机器学习对用户行为建立Profile以实现实时智能实时地保护 Hadoop 生态系统中大数据的安 w397090770 7年前 (2018-01-07) 3190℃ 0评论8喜欢
Apache SystemML 是由 IBM 开发并开源的优化大数据机器学习平台,为使用大数据的机器学习提供了最佳的工作场所。 它可以在 Apache Spark上运行,会自动缩放数据,逐行确定代码是否应在驱动程序或 Apache Spark 群集上运行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopSystemML 是声明式机器 w397090770 7年前 (2018-01-07) 1622℃ 0评论9喜欢
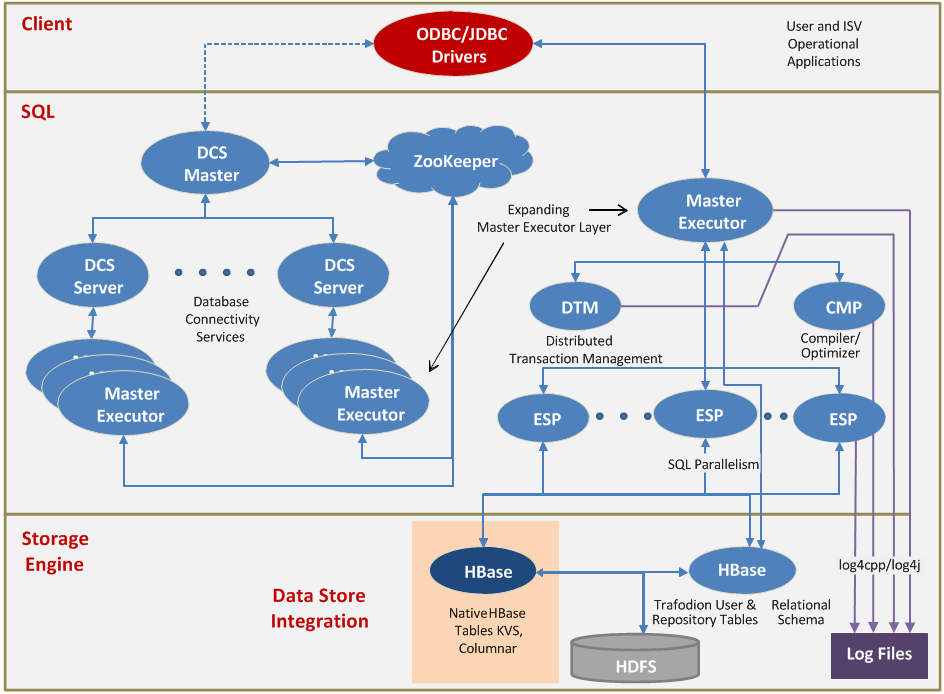
Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:完整的ANSI SQL语言支持完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护支持多种异构存储引擎的直接访问为应 w397090770 7年前 (2018-01-07) 2415℃ 0评论5喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的 w397090770 7年前 (2018-01-01) 3536℃ 0评论10喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase w397090770 7年前 (2017-12-16) 1818℃ 0评论13喜欢