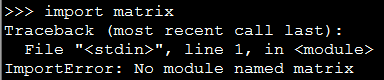
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 56926℃ 0评论14喜欢
如果你使用Apache Spark解决了中等规模数据的问题,但是在海量数据使用Spark的时候还是会遇到各种问题。High Performance Spark将会向你展示如何使用Spark的高级功能,所以你可以超越新手级别。本书适合软件工程师、数据工程师、开发者以及Spark系统管理员的使用。本书全名High Performance Spark:Best Practices for Scaling and Optimizing Apache Spark,作 w397090770 7年前 (2017-06-23) 10560℃ 0评论19喜欢
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种序列化数据结构的方法。对于通过管线(pipeline)或存储数据进行通信的程序开发上是很有用的。这个方法包含一个接口描述 w397090770 7年前 (2017-06-22) 2676℃ 0评论7喜欢
本书作者:Bill Chambers、Matei Zaharia、Shrey Mehrotra,由O'Reilly Media出版社于2017年1月出版,全书共450页。这里提供的是本书的 Early Release 版本,正式版尚未出版,而且目前还没有完整的内容。由于这本书有Matei Zaharia参与编写,所有很值得一看。通过本书将学习到以下的知识:Get a gentle overview of big data and SparkLearn about DataFrames, SQL, a zz~~ 7年前 (2017-06-22) 6719℃ 0评论26喜欢
sftp是Secure File Transfer Protocol的缩写,中文名称安全文件传送协议。其可以为传输文件提供一种安全的加密方法。sftp 与 ftp 有着几乎一样的语法和功能。SFTP 为 SSH的一部分,是一种传输档案至 Blogger 伺服器的安全方式。其实在SSH软件包中,已经包含了一个叫作SFTP(Secure File Transfer Protocol)的安全文件传输子系统,SFTP本身没有单独的守护 w397090770 7年前 (2017-06-21) 43926℃ 0评论21喜欢
Spark Summit 2017会议于2017年06月05日至07日在旧金山(San Francisco)进行,全部会议一共179个。从会议我们得到目前的Spark发展方向主要包括两大主题:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2016年是深度学习之年,而 w397090770 7年前 (2017-06-18) 1921℃ 0评论4喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 7年前 (2017-06-08) 4155℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3519℃ 0评论21喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 7年前 (2017-06-02) 189℃ 0评论0喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 7年前 (2017-06-01) 2576℃ 1评论10喜欢

![[电子书]High Performance Spark完整版PDF下载](https://www.iteblog.com/pic/books/High_Performance_Spark_iteblog.jpg)

![[电子书]Spark: The Definitive Guide Early Release PDF下载](https://www.iteblog.com/pic/books/Spark_The_Definitive_Guide_iteblog.jpg)

![Spark Summit 2017 SanFrancisco全部PPT下载[共143个]](https://www.iteblog.com/pic/spark-summit-2017-SanFrancisco.png)



