Apache Flink 1.1.4于2016年12月21日正式发布,本版本是Flink的最新稳定版本,主要以修复Bug为主;强烈推荐所有的用户升级到Flink 1.1.4版本,替换pom中的以为如下:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.4</version></dependency><dependency> & w397090770 8年前 (2016-12-27) 2296℃ 0评论3喜欢
如果你对Hadoop有基本的了解,并希望将您的知识用于企业的大数据解决方案,那你就来阅读本书吧。本书提供了六个使用Hadoop生态系统解决实际问题的例子,使得您的Hadoop知识提升到一个新的水平。本书作者:Anurag Shrivastava,由Packt出版社于2016年9月出版,全书共316页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 zz~~ 8年前 (2016-12-20) 3226℃ 1评论6喜欢
本书介绍了如何使用 Spark Streaming 开发应用程序已经一些最佳实践。适合数据科学家、大数据专家、BI分析以及数据架构师阅读。全书名称:Pro Spark Streaming The Zen of Real-Time Analytics Using Apache Spark,作者Nabi, Zubair,由Apress于2016-07-01出版,全书共231页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog zz~~ 8年前 (2016-12-18) 4560℃ 0评论6喜欢
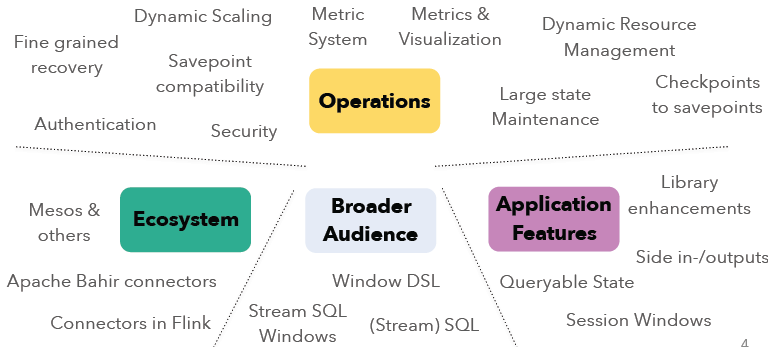
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 8年前 (2016-12-18) 2766℃ 0评论4喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 zz~~ 8年前 (2016-12-16) 17136℃ 0评论42喜欢
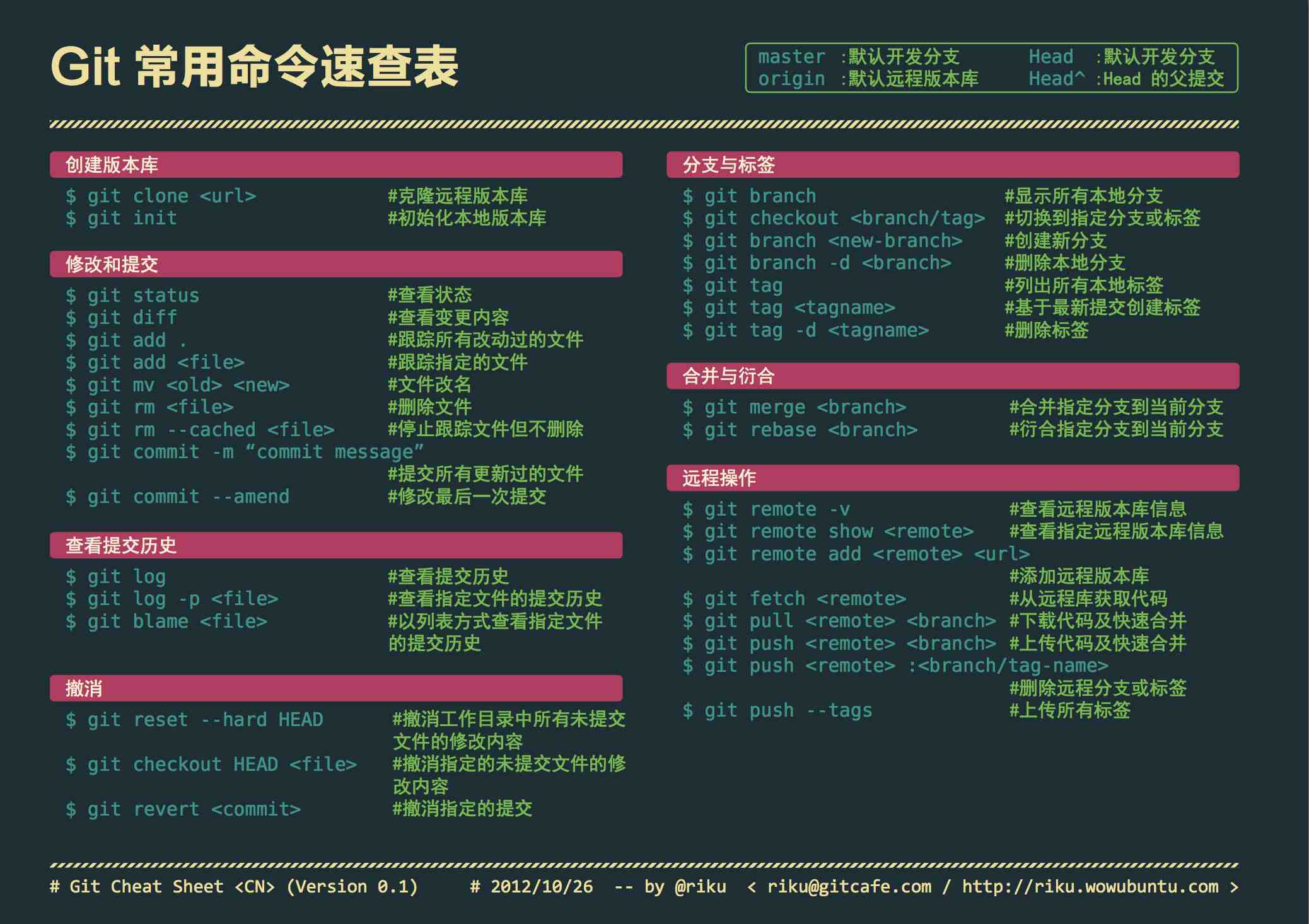
本文列出Git常用命令,点击下图查看大图如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop入门[code lang="bash"]git initorgit clone url[/code]配置[code lang="bash"]git config --global color.ui truegit config --global push.default currentgit config --global core.editor vimgit config --global user.name "John Doe" w397090770 8年前 (2016-12-16) 2374℃ 0评论2喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 w397090770 8年前 (2016-12-15) 3214℃ 0评论8喜欢
本书是《Spark快速数据处理》第三版,全书基于Spark 2.0.0编写。本书适合Spark入门者,作者Krishna Sankar,由Packt出版社于2016年10月出版,全书共274页。通过本书你将学到以下知识: (1)、安装和设置你的Spark集群; (2)、使用Spark交互式Shell来实现简单的分布式应用程序; (3)、使用新的DataFrame API操作数据; w397090770 8年前 (2016-12-14) 4331℃ 0评论5喜欢
Carlos E. Perez对深度学习的2017年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中硬件将加速一倍摩尔定律(即2017年2倍) 如果你跟踪Nvidia和Intel的发展,这当然是显而易见的。Nvidia将在整个2017年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头 w397090770 8年前 (2016-12-13) 2165℃ 0评论3喜欢
在HDFS中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。 w397090770 8年前 (2016-12-13) 5805℃ 0评论13喜欢


![[电子书]Hadoop Blueprints pdf下载](https://www.iteblog.com/pic/Hadoop_Blueprints-iteblog.jpg)
![[电子书]Pro Spark Streaming pdf电子书下载](https://www.iteblog.com/pic/Pro_Spark_Streaming.jpg)
![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)

![[电子书]Fast Data Processing with Spark 2, 3rd Edition下载](https://www.iteblog.com/pic/books/Fast_Data_Processing_with_Spark_2_iteblog.jpg)

