今天凌晨(2016-10-05)Apache Spark 2.0.1稳定版正式发布。Apache Spark 2.0.1是一个维护版本,一共处理了300个Issues,推荐所有使用Spark 2.0.0的用户升级到此版本。Apache Spark 2.0为我们带来了许多新的功能: DataFrame和Dataset统一(可以参见《Spark 2.0技术预览:更容易、更快速、更智能》):https://www.iteblog.com/archives/1668.html SparkSession:一个 w397090770 8年前 (2016-10-05) 3158℃ 0评论7喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第五篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-10-02) 5855℃ 0评论3喜欢
有多个地方需要使用Java client: 1、在存在的集群中执行标准的index, get, delete和search 2、在集群中执行管理任务 3、当你要运行嵌套在你的应用程序中的Elasticsearch的时候或者当你要运行单元测试或者集合测试的时候,启动所有节点获得一个Client是非常容易的,最通用的步骤如下所示: 1、创建一个嵌套的 zz~~ 8年前 (2016-10-02) 1119℃ 0评论7喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第五篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 zz~~ 8年前 (2016-10-01) 3830℃ 0评论6喜欢
本博客曾经介绍了《如何手动添加依赖的jar文件到本地Maven仓库》这里的方法非常的简单,而且局限性很大:只能提供给本人开发使用,无法共享给其他需要的人。本文将介绍如何把自己开发出来的Java包发布到Maven中央仓库(http://search.maven.org/),这样任何人都可以搜索到这个包并使用它。如果你现在还不了解Maven是啥东西,请你 w397090770 8年前 (2016-09-27) 9692℃ 2评论23喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3354℃ 0评论7喜欢
搜索API允许开发者执行搜索查询,返回匹配查询的搜索结果。这既可以通过查询字符串也可以通过查询体实现。多索引多类型所有的搜索API都可以跨多个类型使用,也可以通过多索引语法跨索引使用。例如,我们可以搜索twitter索引的跨类型的所有文档。[code lang="java"]$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'[/ zz~~ 8年前 (2016-09-22) 1660℃ 0评论2喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。分享主题1、中国电信在大数据领域上的创新与探索2、函数式编程与RDD3、社交网络中的信息传播4、大数据分析和机器学习5、分布式流式数据处理框架:功能对比以及性能评估详细主 zz~~ 8年前 (2016-09-20) 1790℃ 0评论2喜欢
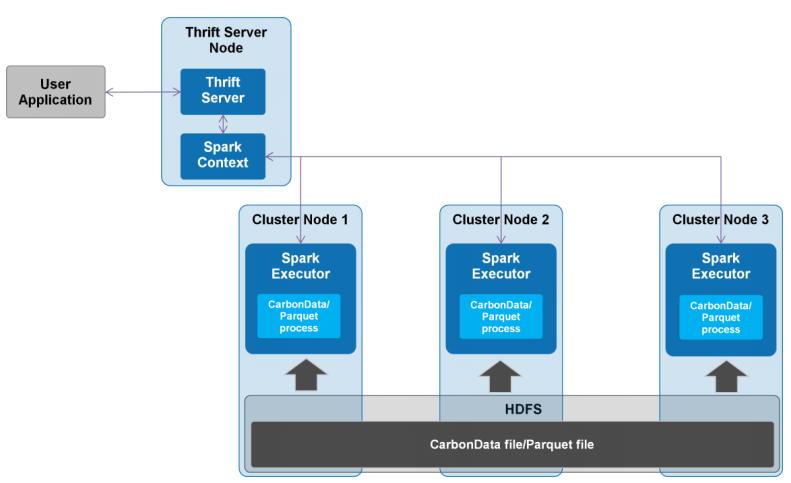
本文相关测试数据由华为陈亮大神提供,特别感谢。 Apache CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化过程中。详细介绍可以参见(《CarbonData:华为开发并支持Hadoop的 w397090770 8年前 (2016-09-11) 8187℃ 1评论7喜欢
这是许多kafka使用者经常会问到的一个问题。本文的目的是介绍与本问题相关的一些重要决策因素,并提供一些简单的计算公式。越多的分区可以提供更高的吞吐量 首先我们需要明白以下事实:在kafka中,单个patition是kafka并行操作的最小单元。在producer和broker端,向每一个分区写入数据是可以完全并行化的,此时,可 w397090770 8年前 (2016-09-08) 10167℃ 2评论22喜欢