Flink Table API Apache Flink对SQL的支持可以追溯到一年前发布的0.9.0-milestone1版本。此版本通过引入Table API来提供类似于SQL查询的功能,此功能可以操作分布式的数据集,并且可以自由地和Flink其他API进行组合。Tables在发布之初就支持静态的以及流式数据(也就是提供了DataSet和DataStream相关APIs)。我们可以将DataSet或DataStream转成Table;同 w397090770 8年前 (2016-06-16) 4153℃ 0评论5喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3360℃ 0评论9喜欢
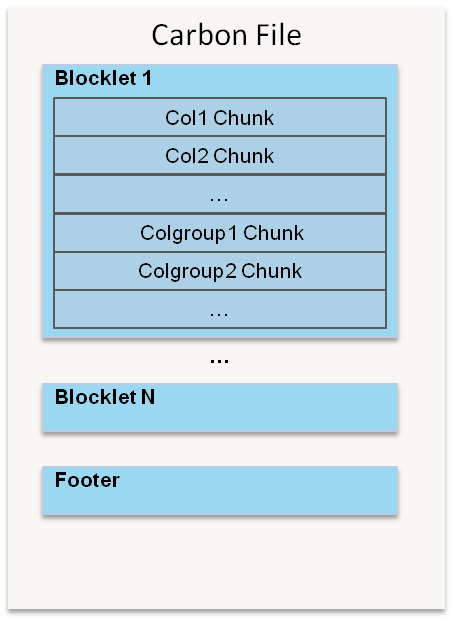
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 8年前 (2016-06-13) 5475℃ 0评论7喜欢
Shanghai Apache Spark Meetup第九次聚会将在6月18日下午13:00-17:00由Intel联手饿了么在上海市普陀区金沙江路1518弄2号近铁城市广场饿了么公司5楼会议室(榴莲酥+螺狮粉)举行。欢迎大家前来参加!会议主题开场/Opening Keynote: 毕洪宇,饿了么数据运营部副总监 毕洪宇个人介绍:饿了么数据运营部副总监。本科和研究生都是同济 w397090770 8年前 (2016-06-12) 1757℃ 0评论5喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 8年前 (2016-06-08) 11229℃ 0评论13喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 8年前 (2016-06-06) 2272℃ 0评论2喜欢
在即将发布的Apache Spark 2.0中将会提供机器学习模型持久化能力。机器学习模型持久化(机器学习模型的保存和加载)使得以下三类机器学习场景变得容易: 1、数据科学家开发ML模型并移交给工程师团队在生产环境中发布; 2、数据工程师把一个Python语言开发的机器学习模型训练工作流集成到一个Java语言开发的机器 w397090770 8年前 (2016-06-04) 3430℃ 3评论3喜欢
随着大数据技术的发展,HDFS作为Hadoop的核心模块之一得到了广泛的应用。为了系统的可靠性,HDFS通过复制来实现这种机制。但在HDFS中每一份数据都有两个副本,这也使得存储利用率仅为1/3,每TB数据都需要占用3TB的存储空间。随着数据量的增长,复制的代价也变得越来越明显:传统的3份复制相当于增加了200%的存储开销,给存 w397090770 8年前 (2016-05-30) 9022℃ 0评论36喜欢
本文原文:Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine:https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html本文已经投稿自:http://geek.csdn.net/news/detail/77005 《Spark 2.0技术预览:更容易、更快速、更智能》文中简单地介绍了Spark 2.0相关 w397090770 8年前 (2016-05-27) 5950℃ 1评论16喜欢
在Spark 1.x版本,我们收到了很多询问SparkContext, SQLContext和HiveContext之间关系的问题。当人们想使用DataFrame API的时候把HiveContext当做切入点的确有点奇怪。在Spark 2.0,引入了SparkSession,作为一个新的切入点并且包含了SQLContext和HiveContext的功能。为了向后兼容,SQLContext和HiveContext被保存下来。SparkSession拥有许多特性,下面将展示SparkS w397090770 8年前 (2016-05-26) 14001℃ 0评论13喜欢


![Spark Summit 2016 San Francisco PPT免费下载[共95个]](https://www.iteblog.com/pic/iteblog.png)