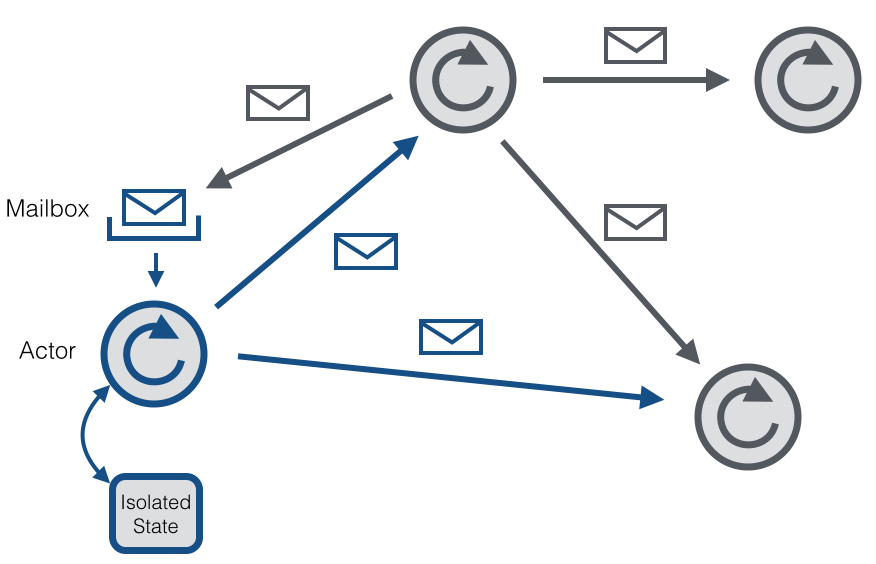
Akka与Actor 模型 Akka是一个用来开发支持并发、容错、扩展性的应用程序框架。它是actor model的实现,因此跟Erlang的并发模型很像。在actor模型的上下文中,所有的活动实体都被认为是互不依赖的actor。actor之间的互相通信是通过彼此之间发送异步消息来实现的。每个actor都有一个邮箱来存储接收到的消息。因此每个actor都维护着 w397090770 8年前 (2016-04-15) 3257℃ 0评论2喜欢
Apache HBase 1.2.1 于2016-04-12正式发布了,HBase 1.2.1是HBase 1.2.z版本线上的第一个维护版本,该版本的主题仍然是为Hadoop和NoSQL社区带来稳定和可靠的数据库。此版本在1.2.0版本上解决了27个issues。主要的Bug修改* [HBASE-15441] - Fix WAL splitting when region has moved multiple times* [HBASE-15219] - Canary tool does not return non-zero exit code when w397090770 8年前 (2016-04-14) 3111℃ 0评论2喜欢
前言 如果你尝试使用Apache Log4J中的DailyRollingFileAppender来打印每天的日志,你可能想对那些日志文件指定一个最大的保存数,就像RollingFileAppender支持maxBackupIndex参数一样。不过遗憾的是,目前版本的Log4j (Apache log4j 1.2.17)无法在使用DailyRollingFileAppender的时候指定保存文件的个数,本文将介绍如何修改DailyRollingFileAppender类,使得它 w397090770 8年前 (2016-04-12) 5574℃ 0评论3喜欢
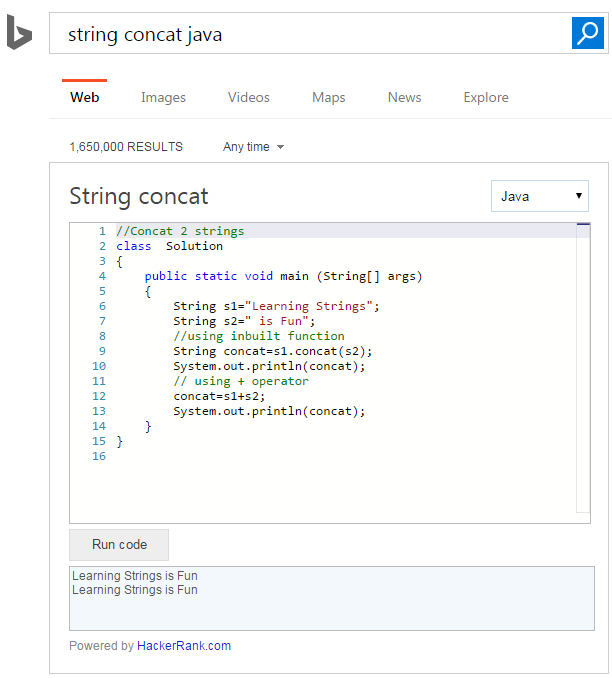
微软的搜索引擎Bing和HackerRank合作,在Bing的搜索结果里面加入了实时代码编辑器,它为数以百万计的程序员提供了一种简单的方法来搜索结果,主要是允许程序员在搜索结果中直接编辑和执行代码示例,实时查看运行结果。 通常情况下,工程师需要到Stackoverflow, Stackexchange或者其他的博客搜索他们需要的答案。现在我们有 w397090770 8年前 (2016-04-11) 1723℃ 0评论2喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 8年前 (2016-04-09) 6623℃ 0评论6喜欢
SQL Join对于初学者来说是比较难得,Join语法有很多inner的,有outer的,有left的,有时候,对于Select出来的结果集是什么样子有点不是很清楚。下图可以帮助初学者理解它。 w397090770 8年前 (2016-04-09) 28730℃ 0评论3喜欢
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图像处理类库,名为:GraphFrames,该类库是构建在DataFrame之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。什么是GraphFrames 与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame因此GraphFrames与G w397090770 8年前 (2016-04-09) 4716℃ 0评论6喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Scala 程序。构建工具 Flink工程可以使用不同的工具进行构建,为了快速构建Flink工程, Flink为下面的构建工具分别提供了模板: 1、SBT 2、Maven这些模板可以帮助我们组织项目结构并初始化一些构建文件。SBT创建工程1、使用Giter8可以使用下 w397090770 8年前 (2016-04-07) 10128℃ 0评论8喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 8年前 (2016-04-06) 13851℃ 0评论8喜欢
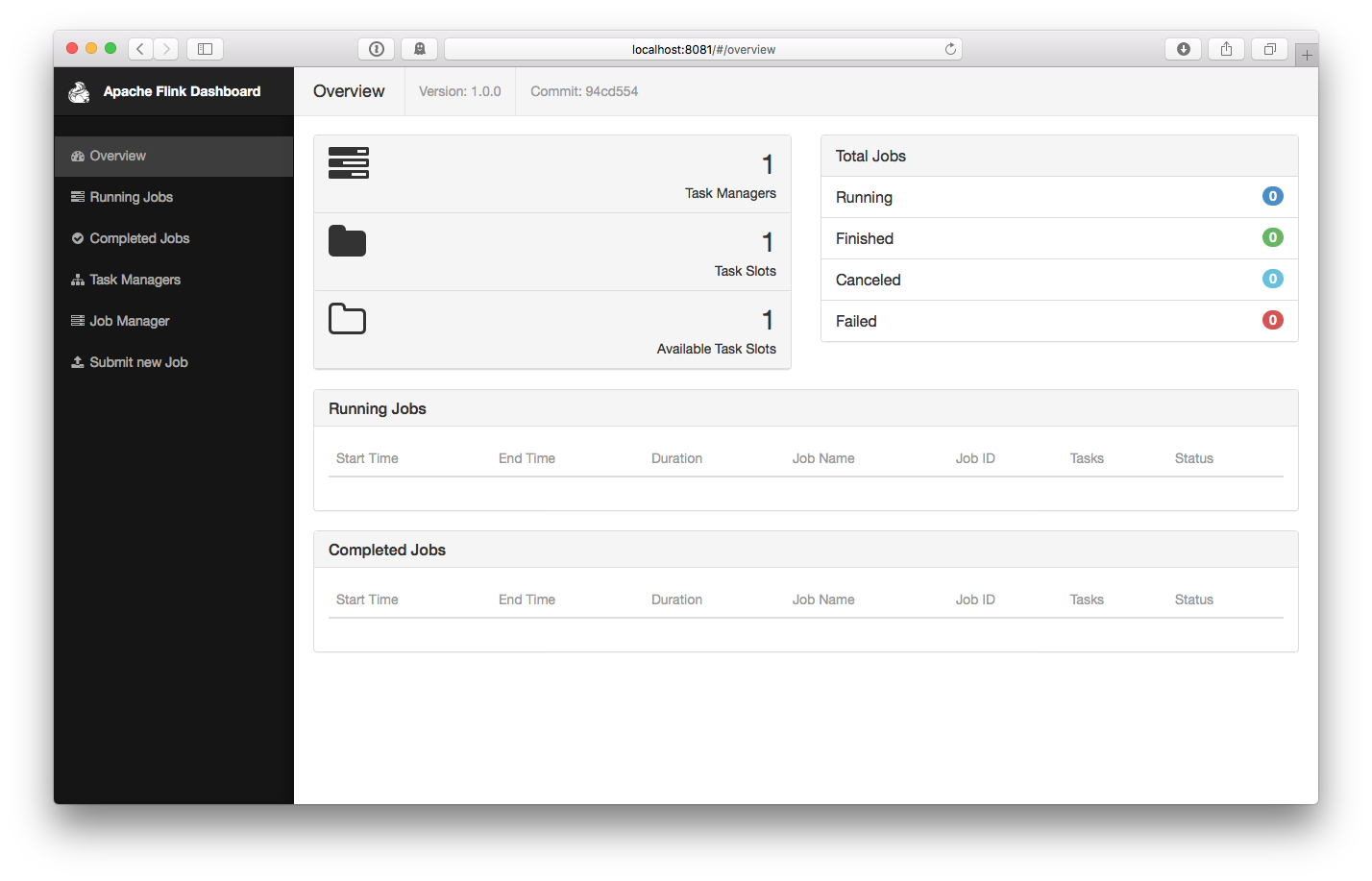
安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结 w397090770 8年前 (2016-04-05) 17641℃ 0评论23喜欢