今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的...... w397090770 6年前 (2019-08-13) 5681℃ 2评论33喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀...... w397090770 6年前 (2019-02-24) 4765℃ 0评论11喜欢
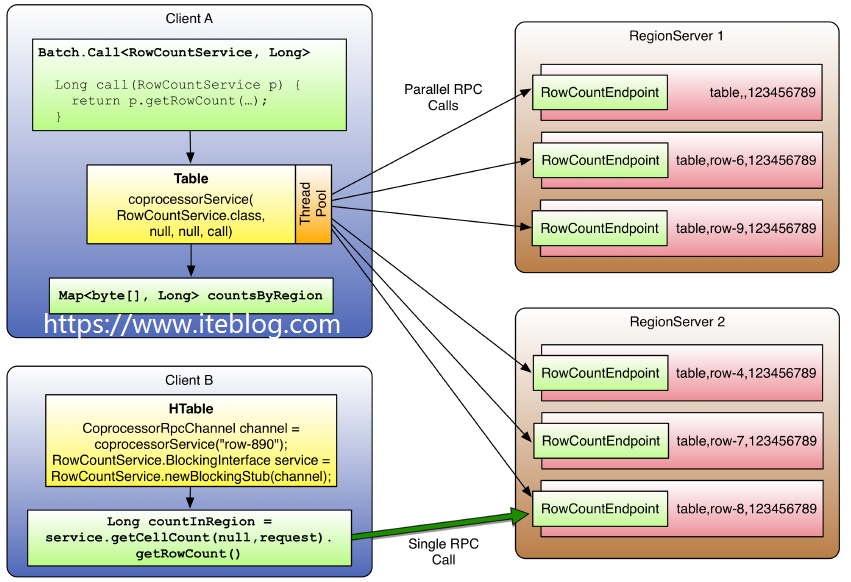
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计...... w397090770 6年前 (2019-02-17) 6358℃ 2评论13喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;...... w397090770 7年前 (2017-12-16) 1822℃ 0评论13喜欢
Apache软件基金会在2017年01月10正式宣布Apache Beam从孵化项目毕业,成为Apache的顶级项目。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金...... w397090770 8年前 (2017-01-12) 3185℃ 0评论7喜欢
我们都知道,当我们的页面请求一个js文件、一个cs文件或者点击到其他页面,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。Referrer 在分析用户的来源时非常有用,比如大家熟悉的百度统计里面就利用到 Referrer 信息了。但是遗憾的是,目前百度统计仅仅支持...... w397090770 8年前 (2017-01-10) 24555℃ 0评论19喜欢
这本书是市面上第一本系统介绍Apache Flink的图书,书中介绍了为什么选择Apache Flink、流系统架构设计、Flink能做些什么、Flink中是怎么处理时间的、Flink的状态计算等。全书共6章,一共110页。由O'Reilly出版社于2016年10月出版。如果想及时了解Spark、Hadoop或者Hb...... w397090770 9年前 (2016-11-03) 7994℃ 0评论4喜欢
本博客曾经介绍了《如何手动添加依赖的jar文件到本地Maven仓库》这里的方法非常的简单,而且局限性很大:只能提供给本人开发使用,无法共享给其他需要的人。本文将介绍如何把自己开发出来的Java包发布到Maven中央仓库(http://search.maven.org/),这样任何人都可以搜索...... w397090770 9年前 (2016-09-27) 9813℃ 2评论23喜欢
一般我们都是用SBT来维护Scala工程,但是在国内网络环境下,使用SBT来创建Scala工程一般都很难成功,或者等待很长的时间才创建完成,所以不建议使用。不过我们也是可以使用Maven来创建Scala工程。在命令行使用下面语句即可创建Scala工程:/** * User: 过往记忆 *...... w397090770 10年前 (2015-05-24) 23439℃ 1评论17喜欢






![[电子书]Introduction to Apache Flink PDF下载](https://www.iteblog.com/pic/books/Introduction_to_Apache_Flink_iteblog.jpg)

